Crecimiento/Primer día personalizado/Tareas estructuradas/Añadir una imagen
Esta página describe el trabajo en una tarea estructurada de "añadir una imagen", que es un tipo de tarea estructurada que el equipo de Crecimiento ofrecerá a través de la página de inicio para recién llegados.
|
Add an image
Suggest images from Commons that newcomers could add to Wikipedia articles
|

Esta página contiene los principales elementos, diseños, preguntas abiertas y decisiones.
Este proyecto en pocas palabras:
|
La mayoría de las actualizaciones sobre el progreso se publicarán en la página general de Actualizaciones del equipo de crecimiento, con algunas actualizaciones grandes o detalladas publicadas aquí.
Estado actual
- 2020-06-22: reflexión inicial sobre las ideas para crear un algoritmo sencillo de recomendación de imágenes
- 2020-09-08: evaluó un primer intento de algoritmo de comparación en inglés, francés, árabe, coreano, checo y vietnamita
- 2020-09-30: evaluó un segundo intento de algoritmo de comparación en inglés, francés, árabe, coreano, checo y vietnamita
- 2020-10-26: Discusión interna sobre la viabilidad del servicio de recomendación de imágenes
- 2020-12-15: realizar una ronda inicial de pruebas con los usuarios para empezar a entender si los recién llegados pueden tener éxito con esta tarea
- 2021-01-20: Nuestro equipo de ingeniería de plataformas comienza a construir una prueba de concepto de la API para las recomendaciones de imágenes.
- 2021-01-21: El equipo de Android comienza a trabajar en una versión mínima viable para el aprendizaje
- 2021-01-28: publicación de resultados de las pruebas de usuarios
- 2021-02-04: Publicación de un resumen del debate comunitario y de las estadísticas de cobertura.
- 2021-05-07: El MVP de Android se pone a disposición de los usuarios
- 2021-08-06: resultados publicados de Android y maquetas para la Iteración 1
- 2021-08-17: Comienza el trabajo backend en la Iteración 1
- 2021-08-23: publicación de prototipos interactivos y comienzo de las pruebas de usuario en inglés y español
- 2021-10-07: resultados publicados de las pruebas de usuarios y diseños finales basados en los datos obtenidos
- 2021-11-19: El embajador comienza a probar la función en sus Wikipedias de producción
- 2021-11-22: el conjunto de datos de sugerencia de imágenes se actualiza antes de entregar la Iteración 1 a los usuarios
- 2021-11-29: Iteración 1 desplegada al 40% de cuentas móviles en las wikis árabe, checa y bengalí.
- 2021-12-22: principales indicadores publicados
- 2022-01-28: versión de escritorio desplegada para el 40% de las nuevas cuentas en las Wikipedias árabe, checa y bengalí.
- 2022-02-16: Los recién llegados a la Wikipedia en español empiezan a recibir "añadir una imagen"
- 2022-03-22: Los recién llegados a la Wikipedia en portugués, farsi, francés y turca empiezan a recibir "añadir una imagen"
- 2023-02-07: Evaluación completa de las sugerencias de imágenes para secciones (T316151)
- 2023-10-16: Image Recommendations added to the Android Wikipedia app
- 2024-04-11: Publish "Add an image" Experiment Analysis
- Siguiente: Release "Add an image" to more Wikipedias
Resumen
Las tareas estructuradas tienen como objetivo dividir las tareas de edición en flujos de trabajo paso a paso que tengan sentido para los recién llegados y para los dispositivos móviles. El equipo de Crecimiento piensa que la introducción de estos nuevos tipos de flujos de edición permitirá que más personas nuevas comience a participar en Wikipedia, algunas de las cuales aprenderán a hacer ediciones más sustanciales y se involucrarán con sus comunidades. Después de discutir la idea de las tareas estructuradas con las comunidades, decidimos crear la primera tarea estructurada: "añadir un enlace".
Después de desplegar "añadir un enlace" en mayo de 2021, recogimos datos iniciales que mostraban que la tarea era atractiva para los recién llegados y que hacían ediciones con bajas tasas de reversión, lo que indica que las tareas estructuradas parecen valiosas para la experiencia de los recién llegados y las wikis.
Mientras construíamos esa primera tarea, estuvimos pensando en cuál podría ser la siguiente tarea estructurada, y creemos que añadir imágenes podría ser una buena opción para los recién llegados. La idea es que un simple algoritmo recomiende imágenes de Commons para colocarlas en artículos que no tienen imágenes. Para empezar, utilizaría sólo las conexiones existentes que se pueden encontrar en Wikidata, y los recién llegados usarían su sentido común para colocar la imagen en el artículo o no.
Sabemos que hay muchas preguntas abiertas sobre cómo funcionará este sistema, y también muchas razones posibles para que no salga bien. Por eso queremos escuchar a muchos miembros de la comunidad y mantener un debate continuo mientras decidimos cómo proceder.
Proyectos relacionados
El equipo de Android ha trabajado en una versión mínima de una tarea similar para la aplicación de Wikipedia para Android utilizando los mismos componentes de base.
Además, el equipo de Datos estructurados está en las primeras fases de estudio de algo similar, dirigido a usuarios más experimentados y que se beneficie de Datos estructurados en Commons.
¿Por qué imágenes?
| Ampliar para leer la sección "¿Por qué imágenes?" |
|---|
|
Buscando contribuciones relevantes Cuando comentamos por primera vez las tareas estructuradas con los miembros de la comunidad, muchos señalaron que añadir wikilinks no era un tipo de edición especialmente valioso. Los miembros de la comunidad aportaron ideas sobre cómo los recién llegados podrían hacer contribuciones más significativas. Una idea es la de las imágenes. Wikimedia Commons contiene 65 millones de imágenes, pero en muchas Wikipedias, más del 50% de los artículos no tienen imágenes. Creemos que muchas imágenes de Commons pueden hacer que Wikipedia esté sustancialmente más ilustrada. Intereses de los recién llegados Sabemos que muchos recién llegados están interesados en añadir imágenes a Wikipedia. "Añadir una imagen" es una respuesta común que dan los recién llegados en la encuesta de bienvenida para explicar por qué están creando su cuenta. También vemos que una de las preguntas más frecuentes del panel de ayuda es sobre cómo añadir imágenes, algo que ocurre en todas las wikis con las que trabajamos. Aunque la mayoría de estos recién llegados probablemente traen su propia imagen que quieren añadir, esto indica que las imágenes pueden resultar atractivas y estimulantes. Esto tiene sentido, dados los elementos de imagen de las otras plataformas en las que participan los recién llegados, como Instagram y Facebook. Dificultades de trabajar con imágenes Las numerosas preguntas del panel de ayuda sobre las imágenes reflejan que el proceso para añadirlas a los artículos es muy complicado. Los recién llegados tienen que entender la diferencia entre Wikipedia y Commons, las reglas en torno a los derechos de autor y las partes técnicas de insertar y subtitular la imagen en el lugar correcto. Encontrar una imagen en Commons para un artículo no ilustrado requiere aún más habilidades, como el conocimiento de Wikidata y las categorías. Éxito de la campaña "Páginas de Wikipedia que quieren fotos" La campaña Wikipedia Pages Wanting Photos (WPWP) fue un éxito sorprendente: 600 personas añadieron imágenes a 85.000 páginas. Lo hicieron con la ayuda de un par de herramientas comunitarias que identificaban las páginas que no tenían imágenes y que sugerían posibles imágenes a través de Wikidata. Aunque aún quedan importantes aspectos que comprender sobre cómo ayudar a los recién llegados a tener éxito con la adición de imágenes, esto nos da la certeza de que a los usuarios pueden ser entusiastas sobre la adición de imágenes y de que con las herramientas se les puede ayudar. Tomando todo esto en conjunto Considerando toda esta información, pensamos que podría ser posible construir una tarea estructurada de "añadir una imagen" que sea divertida para los recién llegados y productiva para las Wikipedias. |
Validación de ideas
Desde junio de 2020 hasta julio de 2021, el equipo de Crecimiento trabajó en discusiones con la comunidad, investigación de fondo, evaluaciones y pruebas de concepto en torno a la tarea de "añadir una imagen". Esto llevó a la decisión de empezar a construir nuestra primera iteración en agosto de 2021 (ver Iteración 1). Esta sección contiene todo ese trabajo de fondo que lleva a la Iteración 1.
| Ampliar para leer la sección "Validación de ideas" | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
AlgoritmoNuestra capacidad de hacer una tarea estructurada para añadir imágenes depende de que podamos crear un algoritmo que genere recomendaciones suficientemente buenas. Definitivamente, no queremos instar a los recién llegados a que añadan las imágenes equivocadas a los artículos, lo que causaría trabajo a los patrulleros para limpiarlas. Por eso, una de las primeras cuestiones que hemos estudiado es si podemos crear un buen algoritmo.
LógicaHemos estado trabajando con el equipo de investigación de Wikimedia, y por ahora hemos estado probando un algoritmo que prioriza la precisión y el juicio humano. En lugar de utilizar cualquier tipo de visión informática, que podría generar resultados inesperados, simplemente agrega la información existente en Wikidata, basándose en las conexiones realizadas por colaboradores experimentados. Estas son las tres formas principales en las que sugiere coincidencias con los artículos no ilustrados:
El algoritmo también incluye una lógica para realizar cosas como excluir imágenes que probablemente sean iconos o que estén presentes en un artículo como parte de un navbox.
PrecisiónDesde agosto de 2021, hemos llevado a cabo tres rondas de pruebas del algoritmo, cada vez examinando las coincidencias con artículos en seis idiomas: inglés, francés, árabe, vietnamita, checo y coreano. Las evaluaciones fueron realizadas por los embajadores de nuestro equipo y otros wikimedistas expertos, que son hablantes nativos de los idiomas probados. Primeras dos evaluaciones Al ver las 50 coincidencias sugeridas en cada idioma, las revisamos y las clasificamos en estos grupos:
Una cuestión que se plantea a lo largo de todo el trabajo sobre un algoritmo como éste es: ¿qué grado de precisión debe tener? Si el 75% de las coincidencias son buenas, ¿es suficiente? ¿Necesita una precisión del 90%? ¿O puede tener una precisión de tan sólo el 50%? Esto depende del buen juicio de los novatos que lo utilicen y de la paciencia que tengan con las coincidencias dudosas. Sabremos más sobre esto cuando probemos el algoritmo con usuarios reales. En la primera evaluación, lo más importante es que encontramos un montón de mejoras fáciles de realizar en el algoritmo, incluyendo tipos de artículos e imágenes a excluir. Incluso sin esas mejoras, alrededor del 20-40% de las coincidencias fueron "2s", lo que significa grandes coincidencias para el artículo (dependiendo de la wiki). Puedes ver los resultados completos y las notas de la primera evaluación aquí. Para la segunda evaluación, se incorporaron muchas mejoras, y la precisión aumentó. Entre el 50-70% de las coincidencias fueron "2s" (dependiendo de la wiki). Pero el aumento de la precisión puede disminuir la cobertura, es decir, el número de artículos para los que podemos hacer coincidencias. Utilizando un criterio conservador, el algoritmo sólo puede sugerir decenas de miles de coincidencias en una wiki determinada, aunque esa wiki tenga cientos de miles o millones de artículos. Creemos que ese tipo de volumen sería suficiente para construir una versión inicial de esta función. Puedes ver los resultados completos y las notas de la segunda evaluación aquí. Tercera evaluación En mayo de 2021, el equipo de Datos estructurados realizó una prueba a mayor escala del algoritmo de comparación de imágenes (y del algoritmo MediaSearch) en las Wikipedias en árabe, cebuano, inglés, vietnamita, bengalí y checo. En esta prueba, unas 500 coincidencias tanto del algoritmo de comparación de imágenes como de MediaSearch fueron evaluadas por expertos en cada idioma, que pudieron clasificarlas como coincidencias "buenas", " aceptables" o "malas". Los resultados que se detallan a continuación así lo demuestran:
Los resultados completos pueden encontrarse aquí.. CoberturaLa precisión del algoritmo es claramente un componente muy importante. Igualmente importante es su "cobertura", que se refiere a "cuántas" coincidencias de imágenes puede hacer. La precisión y la cobertura tienden a estar relacionadas de forma inversa: a mayor precisión del algoritmo, menor número de sugerencias (porque sólo hará sugerencias cuando esté seguro). Tenemos que responder a estas preguntas: ¿es el algoritmo capaz de proporcionar suficientes coincidencias como para que merezca la pena construir una característica con él? ¿Podría tener un impacto sustancial en las wikis? Hemos analizado 22 wikipedias para hacernos una idea de las respuestas. La siguiente tabla muestra el resumen de estos aspectos:
MediaSearchComo se ha mencionado anteriormente, el equipo de Datos estructurados está explorando el uso del algoritmo MediaSearch para aumentar la cobertura y obtener más resultados potenciales. MediaSearch funciona combinando la búsqueda tradicional basada en texto y los datos estructurados para proporcionar resultados relevantes para las búsquedas de manera independiente al idioma. Al utilizar las declaraciones de Wikidata añadidas a las imágenes como parte de Datos estructurados en Commons como entrada para la clasificación de la búsqueda, MediaSearch es capaz de aprovechar los alias, los conceptos relacionados y las etiquetas en varios idiomas para aumentar la relevancia de las coincidencias de las imágenes. Puedes encontrar más información sobre el funcionamiento de MediaSearch aquí. Desde febrero de 2021, el equipo está investigando cómo proporcionar una puntuación de confianza para las coincidencias de MediaSearch que el algoritmo de recomendaciones de imágenes pueda consumir y utilizar para determinar si una coincidencia de MediaSearch es de suficiente calidad para ser utilizada en tareas de emparejamiento de imágenes. Queremos estar seguros de que los usuarios confían en las recomendaciones que MediaSearch proporciona antes de incorporarlas a la función. El equipo de Datos Estructurados también está explorando y creando un prototipo para que los bots generados por el usuario utilicen los resultados generados tanto por el algoritmo de recomendaciones de imágenes como por MediaSearch para añadir automáticamente imágenes a los artículos. Se trata de un experimento en wikis con muchos bots, en colaboración con los creadores de bots de la comunidad. Puedes saber más sobre este proyecto o expresar tu interés en participar en la tarea phabricator. En mayo de 2021, en la misma evaluación citada en la sección "Precisión", MediaSearch resultó ser mucho menos preciso que el algoritmo de comparación de imágenes. Mientras que el algoritmo de comparación de imágenes tenía una precisión del 78%, las coincidencias de MediaSearch tenían una precisión del 38%. Por lo tanto, el equipo de Crecimiento no tiene previsto utilizar MediaSearch en su primera iteración de la tarea "añadir una imagen". Preguntas y discusión
Preguntas abiertasLas imágenes son una parte muy importante y notoria de la experiencia de Wikipedia. Es fundamental que pensemos detenidamente en cómo funcionaría una función que permitiera añadir imágenes de forma sencilla, cuáles podrían ser los posibles obstáculos y cuáles serían las implicaciones para los miembros de la comunidad. Con este fin, tenemos muchas preguntas abiertas, y queremos escuchar otras que los miembros de la comunidad puedan plantear.
Notas de las discusiones comunitarias 04-02-2021Desde diciembre de 2020, invitamos a los miembros de la comunidad a hablar sobre la idea de "añadir una imagen" en cinco idiomas (inglés, bengalí, árabe, vietnamita y checo). La discusión en inglés tuvo lugar principalmente en la página de discusión, con conversaciones en el idioma local en las otras cuatro Wikipedias. Hemos escuchado a 28 miembros de la comunidad, y esta sección resume algunas de las ideas más comunes e interesantes. Estas discusiones están influenciando fuertemente nuestro próximo conjunto de diseños.
Plan para el test de usuario Considerando las preguntas abiertas anteriores, además de las aportaciones de la comunidad, queremos generar alguna información cuantitativa y cualitativa que nos ayude a evaluar la viabilidad de crear una función de "añadir una imagen". Aunque hemos estado evaluando el algoritmo entre el personal y los wikimedistas, es importante ver cómo reaccionan los recién llegados a él, y ver cómo utilizan su juicio a la hora de decidir si una imagen pertenece a un artículo. Para ello, vamos a realizar pruebas con usertesting.com, en las que las personas que son nuevas en la edición de Wikipedia puedan recorrer las posibles coincidencias de imágenes en un prototipo y responder "Sí", "No" o "No estoy seguro". Construimos un prototipo rápido para la prueba, respaldado con coincidencias reales del algoritmo actual. El prototipo sólo muestra una coincidencia tras otra, todas en un feed. Las imágenes se muestran junto con todos los metadatos relevantes de Commons:
Aunque es posible que el flujo de trabajo no sea así para los usuarios reales en el futuro, el prototipo se hizo para que los usuarios probadores pudieran revisar rápidamente muchas coincidencias potenciales, generando mucha información. Para probar el prototipo interactivo, use este enlace. Tenga en cuenta que este prototipo es principalmente para ver las coincidencias del algoritmo - todavía no hemos pensado mucho en la experiencia real del usuario. En realidad, no crea ninguna edición. Contiene 60 coincidencias reales propuestas por el algoritmo. Esto es lo que buscaremos en la prueba:
DiseñoConcepto A vs. BAl pensar en el diseño de esta tarea, tenemos una cuestión similar a la que nos enfrentamos para "añadir un enlace" con respecto al Concepto A y al Concepto B. En el Concepto A, los usuarios completarían la edición en el artículo, mientras que en el Concepto B, harían muchas ediciones seguidas todas desde un feed. El Concepto A da al usuario más contexto para el artículo y la edición, mientras que el Concepto B prioriza la eficiencia. En el prototipo interactivo anterior, utilizamos el Concepto B, en el que los usuarios avanzan a través de un feed de sugerencias. Lo hicimos así porque en nuestras pruebas de usuario queríamos ver muchos ejemplos de usuarios interactuando con las sugerencias. Ese es el tipo de diseño que podría funcionar mejor para una plataforma como la aplicación de Wikipedia para Android. Para el contexto del equipo de Crecimiento, estamos pensando más en la línea del Concepto A, en el que el usuario hace la edición "en el artículo". Esa es la dirección que elegimos para "añadir un enlace", y creemos que podría ser apropiada para "añadir una imagen" por las mismas razones. Invidual vs. MuúltipleOtra cuestión importante de diseño es si se debe mostrar al usuario una "única" imagen propuesta que coincida, o darle varias imágenes que coincidan para que elija. Si se ofrecen varias correspondencias, hay más posibilidades de que una de ellas sea buena. Pero también puede hacer que los usuarios piensen que deben elegir una de ellas, aunque ninguna sea buena. Además, será una experiencia más complicada de diseñar y construir, especialmente para los dispositivos móviles. Hemos hecho un simulacro de tres posibles flujos de trabajo:
   Tests de usuarios Diciembre 2020Antecendentes Durante diciembre de 2020, utilizamos usertesting.com para realizar 15 pruebas del prototipo interactivo móvil. El prototipo contenía sólo un diseño rudimentario, poco contexto o onboarding, y fue probado sólo en inglés con usuarios que tenían poca o ninguna experiencia previa en la edición de Wikipedia. Probamos deliberadamente un diseño rudimentario en las primeras fases del proceso para poder reunir muchos aprendizajes. Las principales cuestiones que queríamos abordar con esta prueba se referían a la "viabilidad" de la función en su conjunto, no a los detalles del diseño:
En el test, pedimos a los participantes que anotaran al menos 20 coincidencias entre artículos e imágenes mientras hablaban en voz alta. Cuando marcaban "sí", el prototipo les pedía que escribieran un pie de foto que acompañara a la imagen del artículo. En total, recogimos 399 anotaciones. Resumen Creemos que estas pruebas de usuario confirman que podríamos crear con éxito una función de "añadir una imagen", pero sólo funcionará si la diseñamos bien. Muchos de los probadores entendieron bien la tarea, se la tomaron en serio y tomaron buenas decisiones, lo que nos hace confiar en que es una idea que merece la pena llevar a cabo. Por otro lado, muchos otros usuarios estaban confundidos sobre el sentido de la tarea, no la evaluaron tan críticamente, y tomaron decisiones débiles -- pero para esos usuarios confusos, fue fácil para nosotros encontrar maneras de mejorar el diseño para darles el contexto apropiado y transmitir la importancia de la tarea. Observaciones Para ver el conjunto de conclusiones, puedes consultar las diapositivas. Los puntos más importantes están escritos al pie de las diapositivas. 
Métricas
Para llevar a cabo
MetadatosLas pruebas con usuarios nos mostraron que los metadatos de las imágenes de Commons (por ejemplo, el nombre del archivo, la descripción, el pie de foto, etc.) son fundamentales para que un usuario pueda establecer una correspondencia con garantías. Por ejemplo, aunque el usuario puede ver que el artículo trata de una iglesia y que la foto es de una iglesia, los metadatos le permiten saber si es "la" iglesia de la que se habla en el artículo. En las pruebas de usuarios, vimos que estos elementos de metadatos eran los más importantes: nombre del archivo, descripción, pie de foto, categorías. Los elementos que no eran útiles eran el tamaño, la fecha de subida y el nombre del usuario que la realizó. Dado que los metadatos son una parte fundamental a la hora de tomar una decisión firme, hemos pensado si los usuarios necesitarán tener metadatos en su propio idioma para poder realizar esta tarea, especialmente teniendo en cuenta que la mayoría de los metadatos de Commons están en inglés. Para 22 wikis, observamos el porcentaje de las coincidencias de imágenes del algoritmo que tienen elementos de metadatos en el idioma local. En otras palabras, para las imágenes que pueden coincidir con artículos no ilustrados en la Wikipedia árabe, ¿cuántas de ellas tienen descripciones, pies de foto y representaciones en árabe? La tabla se encuentra debajo de estos puntos de resumen:
Dado que los metadatos en el idioma local tienen poca cobertura, nuestra idea actual es ofrecer la tarea de concordancia de imágenes sólo a aquellos usuarios que sepan leer en inglés, lo que podríamos plantear al usuario como una pregunta rápida antes de comenzar la tarea. Lamentablemente, esto limita el número de usuarios que pueden participar. Es una situación similar a la de la herramienta Traducción de contenidos, en el sentido de que los usuarios necesitan conocer el idioma de la wiki de origen y de la wiki de destino para poder mover contenidos de una wiki a otra. También creemos que habrá un número suficiente de este tipo de usuarios basándonos en los resultados de la encuesta de bienvenida del equipo de Crecimiento, que pregunta a los recién llegados qué idiomas conocen. Dependiendo de la wiki, entre el 20% y el 50% de los recién llegados seleccionan el inglés. Android MVPVisita esta página para conocer los detalles sobre el MVP de Android. AntecedentesDespués de muchas discusiones de la comunidad, numerosas discusiones internas, y los resultados de las pruebas de usuarios de arriba, creemos que esta idea de "añadir una imagen" tiene suficiente potencial para seguir adelante. Los miembros de la comunidad han sido generalmente positivos, pero también cautelosos -- también sabemos que todavía hay muchas preocupaciones y razones por las que la idea podría no funcionar como se espera. El siguiente paso que queremos dar para saber más es construir un "producto mínimo viable" (MVP) para la aplicación Android de Wikipedia. Lo más importante de este MVP es que no guardará ninguna edición en Wikipedia. Más bien, sólo se utilizará para recopilar datos, mejorar nuestro algoritmo y mejorar nuestro diseño. La aplicación de Android es donde se originaron las "ediciones sugeridas", y ese equipo tiene un marco para construir nuevos tipos de tareas fácilmente. Estas son las partes principales:
ResultadosEl equipo de Android lanzó la aplicación en mayo de 2021 y, a lo largo de varias semanas, miles de usuarios evaluaron decenas de miles de coincidencias de imágenes del algoritmo de comparación de imágenes. Los datos resultantes permitieron al equipo de Crecimiento decidir seguir con la Iteración 1 de la tarea de "añadir una imagen". Al examinar los datos, tratamos de responder a dos preguntas importantes en torno a la "participación" y la "eficacia". Compromiso: ¿a los usuarios de todos los idiomas les gusta esta tarea y quieren hacerla?
Eficacia: ¿las ediciones resultantes serán de suficiente calidad?
Vea los resultados completos aquí IngenieríaEsta sección contiene enlaces sobre cómo seguir los aspectos técnicos de este proyecto: |
Iteración 1
En julio de 2021, el equipo de Crecimiento decidió seguir adelante con el desarrollo de una primera iteración de una tarea de "añadir una imagen" para la web. Esta fue una decisión difícil, debido a las muchas preguntas abiertas y a los riesgos en torno a animar a los recién llegados a añadir imágenes a los artículos de Wikipedia. Pero después de pasar por un año de validación de la idea, y de ver las discusiones de la comunidad, las evaluaciones, los tests y las pruebas de concepto resultantes en torno a esta idea, decidimos construir una primera iteración para poder seguir aprendiendo. Estas son las principales conclusiones de la fase de validación de la idea que nos llevaron a seguir adelante:
- Apoyo moderado de la comunidad: los miembros de la comunidad son cautelosamente optimistas sobre esta tarea, y están de acuerdo en que sería valiosa, pero señalan muchos riesgos y obstáculos que creemos que podemos abordar con un buen diseño.
- Algoritmo preciso: el algoritmo de coincidencia de imágenes ha demostrado ser un 65-80% preciso a través de múltiples pruebas diferentes, y hemos sido capaces de refinarlo con el tiempo.
- Pruebas de usuarios: muchos recién llegados que experimentaron los prototipos encontraron la tarea divertida y atractiva.
- Android MVP: los resultados del MVP de Android mostraron que los recién llegados en general aplicaron un buen criterio a las sugerencias, pero lo más importante es que nos dieron pistas sobre cómo mejorar sus resultados en nuestros diseños. Los resultados también indicaron que la tarea podría funcionar bien en todos los idiomas.
- Conclusiones generales: al haber tropezado con muchos obstáculos en nuestras diversas etapas de validación, podremos evitarlos en nuestros próximos diseños. Este trabajo de fondo nos ha dado muchas ideas sobre cómo guiar a los recién llegados hacia el buen juicio y cómo evitar ediciones problemáticas.
Hipótesis
No estamos seguros de que esta tarea vaya a funcionar bien, por eso planeamos construirla en pequeñas iteraciones, aprendiendo por el camino. Creemos que podemos hacer un buen intento utilizando lo que hemos aprendido hasta ahora para construir una primera iteración sencilla. Una forma de pensar en lo que estamos haciendo con nuestras iteraciones es la prueba de hipótesis. A continuación se presentan cinco hipótesis optimistas que tenemos sobre la tarea "añadir una imagen". Nuestro objetivo en la Iteración 1 será ver si estas hipótesis son correctas.
- Leyendas: los usuarios pueden escribir leyendas satisfactorias. Esta es nuestra mayor pregunta abierta, ya que las imágenes que se colocan en los artículos de Wikipedia generalmente requieren pies de foto, pero el MVP de Android no probó la capacidad de los novatos para escribirlos bien.
- Eficacia: los recién llegados tendrán el suficiente criterio para que sus ediciones sean aceptadas por las comunidades.
- Engagement: a los usuarios les gusta hacer esta tarea en el móvil, hacer muchas y volver para hacer más.
- Idiomas: los usuarios que no sepan inglés podrán realizar esta tarea. Se trata de una cuestión importante, ya que la mayoría de los metadatos de Commons están en inglés, y es fundamental que los usuarios lean el nombre del archivo, la descripción y el pie de foto de Commons para confirmar con seguridad las coincidencias.
Paradigma: el paradigma de diseño que construimos para "la tarea de añadir un enlace estructurado" se extenderá a las imágenes.
Alcance
Dado que nuestro principal objetivo con la Iteración 1 es el aprendizaje, queremos ofrecer una experiencia a los usuarios lo antes posible. Esto significa que queremos limitar el alcance de lo que construimos para poder liberarlo rápidamente. A continuación se presentan las limitaciones de alcance más importantes que creemos que debemos imponer a la Iteración 1.
- Sólo para móviles: mientras que muchos wikimedistas experimentados hacen la mayor parte del trabajo de la wiki desde su ordenador/computadora de sobremesa/portátil, los recién llegados que se esfuerzan por contribuir a la Wikipedia utilizan mayoritariamente dispositivos móviles, y son la audiencia más importante para el trabajo del equipo de Crecimiento. Si construimos la Iteración 1 sólo para móviles, nos concentraremos en ese público y ahorraremos el tiempo que nos llevaría diseñar y construir adicionalmente el mismo flujo de trabajo para ordenadores/computadoras de sobremesa/portátiles.
- Sugerencias estáticas: en lugar de construir un servicio backend para ejecutar y actualizar continuamente las coincidencias de imágenes disponibles utilizando el algoritmo de coincidencia de imágenes, ejecutaremos el algoritmo una vez y utilizaremos el conjunto estático de sugerencias para la Iteración 1. Aunque esto no permitirá disponer de las imágenes más recientes y los datos más actuales, creemos que será suficiente para nuestro aprendizaje.
- Paradigma de añadir un enlace: nuestro diseño seguirá generalmente los mismos patrones que el diseño de nuestra tarea estructurada anterior, "añadir un enlace".
- Artículos sin ilustraciones: limitaremos nuestras sugerencias sólo a los artículos que no tengan ninguna ilustración, en lugar de incluir artículos que ya tengan algunas, pero que podrían necesitar más. Esto significará que nuestro flujo de trabajo no necesitará incluir pasos para que el recién llegado elija en qué parte del artículo colocar la imagen. Dado que será la única imagen, se puede asumir que es la imagen principal en la parte superior del artículo.
- Sin infoboxes: limitaremos nuestras sugerencias sólo a los artículos que no tengan infoboxes. Esto se debe a que si un artículo no ilustrado tiene una infobox, su primera imagen debería colocarse normalmente en la infobox. Pero es un reto técnico importante asegurarse de que podemos identificar los campos correctos de imagen y pie de foto en todos los infoboxes en muchos idiomas. Esto también evita los artículos que tienen infoboxes de Wikidata.
- Una sola imagen: aunque el algoritmo de comparación de imágenes puede proponer varias imágenes candidatas para un solo artículo no ilustrado, limitaremos la Iteración 1 a proponer sólo la candidata de mayor confianza. Esto hará que la experiencia sea más sencilla para el recién llegado, y que el diseño y el esfuerzo de ingeniería sean más sencillos para el equipo.
- Puertas de calidad: creemos que deberíamos incluir algún tipo de mecanismo automático para evitar que un usuario haga un gran número de ediciones malas en poco tiempo. Las ideas en torno a esto incluyen (a) limitar a los usuarios a un cierto número de ediciones de "añadir una imagen" por día, (b) dar a los usuarios instrucciones adicionales si invierten muy poco tiempo con cada sugerencia, (c) dar a los usuarios instrucciones adicionales si parecen estar aceptando demasiadas imágenes. Esta idea se inspiró en la experiencia de Wikipedia en inglés 2021 con la campaña Páginas de Wikipedia que quieren fotos.
- Wikis piloto: al igual que con todos los nuevos desarrollos de Crecimiento, primero vamos a implementar sólo en nuestras cuatro wikis piloto, que son las Wikipedias árabe, vietnamita, bengalí y checa. Se trata de comunidades que siguen de cerca el trabajo de Growth y son conscientes de que forman parte de experimentos. El equipo de Crecimiento emplea a embajadores de la comunidad para ayudarnos a mantener una correspondencia rápida con esas comunidades. Es posible que el año que viene añadamos las Wikipedias en español y portugués a la lista.
Nos interesa conocer la opinión de los miembros de la comunidad sobre si estas opciones de alcance son buenas, o si alguna parece que limitaría mucho nuestros aprendizajes en la Iteración 1.
Diseño
Mockups y prototipos
Basándonos en los diseños de nuestras pruebas de usuario anteriores y en el MVP de Android, estamos considerando múltiples conceptos de diseño para la Iteración 1. Para cada una de las cinco partes del flujo de usuarios, tenemos dos alternativas. Probaremos ambas para obtener información de los recién llegados. Nuestras pruebas de usuario se llevarán a cabo en inglés y en español: es la primera vez que nuestro equipo realiza pruebas en un idioma distinto del inglés. También esperamos que los miembros de la comunidad analicen los diseños y aporten sus opiniones en la página de discusión.
Prototipos para los test de usuarios
La forma más fácil de experimentar lo que estamos planteando construir es a través de los prototipos interactivos. Hemos construido prototipos para los diseños "Concepto A" y "Concepto B", y están disponibles tanto en inglés como en español. No se trata de un software wiki real, sino de una simulación del mismo. Esto significa que no se guardan las ediciones, y que no todos los botones e interacciones funcionan, pero los más importantes relacionados con el proyecto "añadir una imagen" "sí" funcionan.
Mockups para test de usuarios
A continuación se muestran imágenes estáticas de las maquetas que vamos a utilizar para las pruebas de usuario en agosto de 2021. Los miembros de la comunidad pueden explorar el archivo Figma del diseñador del equipo de crecimiento, que contiene las maquetas que aparecen abajo en la parte inferior derecha del cuadro, así como las diversas piezas de referencia y las notas que condujeron a ellas.
Feed
Estos diseños se refieren a la primera parte del flujo de trabajo, en la que el usuario elige un artículo para trabajar desde el feed de ediciones sugeridas. Queremos que la presentación sea atractiva, pero sin confundir al usuario.
-
 Concepto A: contiene una miniatura oscurecida de la imagen sugerida, dando al usuario algunas indicaciones sobre la tarea que va a realizar.
Concepto A: contiene una miniatura oscurecida de la imagen sugerida, dando al usuario algunas indicaciones sobre la tarea que va a realizar. -
 Concepto B: no hay miniatura de la imagen, para que el usuario no sienta falsamente que la imagen propuesta "pertenece" al artículo.
Concepto B: no hay miniatura de la imagen, para que el usuario no sienta falsamente que la imagen propuesta "pertenece" al artículo.


Onboarding
Estos diseños se refieren a lo que el usuario ve después de abrir su primera tarea, con la intención de explicar en qué consiste la tarea y cómo hacer un buen trabajo. Queremos que el usuario entienda que añadir una imagen es una edición importante que hay que considerar seriamente. Hay que tener en cuenta que este texto exacto no se ha diseñado con cuidado todavía - más bien, estamos pensando ahora en la experiencia a través de la cual entregamos este contenido.
-
 Concepto A: superposiciones a pantalla completa que explican los conceptos y los pasos para añadir una imagen.
Concepto A: superposiciones a pantalla completa que explican los conceptos y los pasos para añadir una imagen. -
 Concepto B: ventanas emergentes secuenciales que señalan los elementos para las diferentes partes del flujo de trabajo.
Concepto B: ventanas emergentes secuenciales que señalan los elementos para las diferentes partes del flujo de trabajo.


Añadiendo la imagen
Estos diseños se refieren a la parte del flujo de trabajo en la que el usuario ve la imagen sugerida, ve sus metadatos de Commons y decide si la añade al artículo. Sabemos por las pruebas de usuarios que es importante que lean el título de la imagen, la descripción de Commons y el pie de foto de Commons para tomar esta decisión correctamente. Esta es la parte más desafiante del diseño: hacer que toda esa información esté disponible en la pantalla del móvil.
-
 Concepto A: la imagen sugerida se muestra en el lugar donde irá en el artículo, dando al usuario la sensación de que al añadir la imagen, de hecho, la pondrá en el artículo. El usuario puede ampliar la imagen para verla a pantalla completa y tocar la "i" para ver más metadatos.
Concepto A: la imagen sugerida se muestra en el lugar donde irá en el artículo, dando al usuario la sensación de que al añadir la imagen, de hecho, la pondrá en el artículo. El usuario puede ampliar la imagen para verla a pantalla completa y tocar la "i" para ver más metadatos. -
 Concepto B: la imagen sugerida se muestra en la pantalla del "inspector de imágenes", junto con los metadatos de Commons que acompañan a la imagen. El usuario puede ampliar la imagen para verla a pantalla completa.
Concepto B: la imagen sugerida se muestra en la pantalla del "inspector de imágenes", junto con los metadatos de Commons que acompañan a la imagen. El usuario puede ampliar la imagen para verla a pantalla completa.


Leyenda y publicación
Estos diseños se refieren a la parte del flujo de trabajo después de que el usuario ha decidido añadir una imagen al artículo, y ahora está escribiendo un pie de foto para acompañarla. Esta puede ser la parte más difícil para los recién llegados, y todavía estamos pensando en cómo ayudarles a entender qué tipo de pie de foto es apropiado.
-
 Concepto A: el subtítulo se añade a través del diálogo de subtítulos del Editor Visual existente en su propia pantalla.
Concepto A: el subtítulo se añade a través del diálogo de subtítulos del Editor Visual existente en su propia pantalla. -
 Concepto B: leyenda añadida en el lugar del artículo, ayudando al usuario a entender el contexto en el que se verá la leyenda.
Concepto B: leyenda añadida en el lugar del artículo, ayudando al usuario a entender el contexto en el que se verá la leyenda.


Rechazo
Cuando un usuario rechaza una sugerencia, queremos recopilar datos sobre la razón por la que la coincidencia fue errónea, para poder mejorar el algoritmo. Esta es también una oportunidad para recordar continuamente al usuario los criterios de evaluación que debe utilizar al evaluar las imágenes.
-
 Concepto A: el usuario sólo puede elegir una opción.
Concepto A: el usuario sólo puede elegir una opción. -
 Concepto B: el usuario puede elegir varias opciones.
Concepto B: el usuario puede elegir varias opciones.


Resultados de las pruebas de usuarios septiembre de 2021
In August 2021, we ran 32 user tests amongst people who were new to Wikipedia editing, using respondents from usertesting.com. Half the respondents walked through Concept A and half through Concept B. In order to represent more diverse perspectives, this was the first time that the Growth team ran user tests outside of English: 11 de las personas encuestadas realizaron el test en español, todas ellas fuera de Estados Unidos. This will help us make sure we're building a feature that is valuable and understandable for populations around the world.
Our goals for the testing were to identify which parts of the design concepts worked best, and to surface any other potential improvements. These are our main findings and changes to the designs we plan to make.
- Findings
- Concept B clearly performed better for participants in both English and Spanish tests, particularly:
- Better understanding of the task. In Concept A, users sometimes thought the image was already in the article, because of its preview on the suggested edit card and the preview in the article.
- More careful engagement and consideration of article contents and image metadata when evaluating image suitability to an article. We suspect this is because the article and metadata areas were clearly separated.
- Greater use of image details and article contents during caption composition. The Concept B caption experience shows the full article text.
- Other notes
- Most people misunderstood the task initially as uploading images when they opened the Suggested edits module, regardless of design. But expectation about self-sourcing images was immediately corrected for almost all participants as soon as they opened the task, and overall, Design B evoked better task comprehension and successful image evaluation than Design A.
- Newcomers would benefit from more user education around Commons and use of images on Wikipedia articles in their understanding of the broader editing ecosystem of Wikipedia and its sister projects.
- Users understood the purpose of the caption, and understood that it would be displayed with the image in the Wikipedia article.
- Spanish participants were far more interwiki-attuned than English participants. Potentially explore ways to better cater to multilingual/cross-wiki users.
- Spanish participants needed to translate Commons metadata to themselves in order to write good captions in Spanish.
- The current task requires several different skills, such as image evaluation, caption writing, and translation (for reading Commons metadata from a non-English Wikipedia). There may be benefits and opportunities for separating out this task into multiple tasks in future so that users don't have to have all the skills in order to complete the task.
- Concept B clearly performed better for participants in both English and Spanish tests, particularly:
- Cambios
- Do not show a preview of the suggested image on the card in the suggested edits feed.
- The onboarding tooltips worked well to help users understand the task. But they could be overwhelming or cluttering for smaller screens. Though we prefer to implement tooltips, we have decided to implement fullscreen overlays for onboarding in Iteration 1, because tooltips will take a substantially longer time to engineer well. We may implement tooltips in a future iteration.
- Image and image metadata need to be next to each other -- when they are in separate parts of the screen, users become confused.
- Because it is very important that users consider image metadata when making their decision and writing the caption, we need to increase the visibility of the metadata with clearer calls to read it.
- Include simple validation on the free-text caption, such as enforcing a minimum length for captions, or not allowing the filename to be part of the caption.
- Provide samples of good and bad captions in the explanation for the caption step.
- When users reject a suggestion and give the reason for the rejection, some of the reasons should not remove the suggestion from the queue, e.g. "I do not know this topic". Perhaps another user will be able to confidently make the match.
- Example captions: below are three image/article pairings used in the test and the actual captions written by user testers. This gives us a sense of the sorts of captions we can expect from newcomers. They all seem to be generally on the right track, though they range from more like "alt text" to more like captions. There are also a couple that miss the mark.
-
 Article: Edward Edwards (Royal navy officer)
Article: Edward Edwards (Royal navy officer)
"Drawing of the HMS Pandora by Robert Batty"
"The HMS Pandora, of which Admiral Edward Edwards captained in order to catch mutineers."
"An 1831 depiction of the HMS Pandora sinking"
"Royal Navy"
"Illustration of HMS Pandora sinking" -
 Artículo: Fiesque
Artículo: Fiesque
"Edouard Lalo, composer of the music of the Fiesque opera"
"Photo of Edouard Lalo, composer of Fiesque"
"Edouard Lalo - 1865"
"Eduard Lalo, around 1865"
Estos pies de imagen fueron traducidos desde el español. -
 Artículo: Bahaettin Rahmi Bediz
Artículo: Bahaettin Rahmi Bediz
"A photo of Bahaettin Rahmi Bediz taken on 1st January 1924, pictured with his bicycle"
"Bahaettin Radmi Bediz on 1 January 1924"
"Rahmizadephoto1869"
"Rahnizade Bahaeddin Bediz. in uniform, standing next to a bicycle"



Diseños finales de la Iteración 1
Based on the user test findings above, we created the set of designs that we are implementing for Iteration 1. The best way to explore those designs is here in the Figma file, which always contains the latest version.
Measurement
Leading indicators
Whenever we deploy new features, we define a set of "leading indicators" that we will keep track of during the early stages of the experiment. These help us quickly identify if the feature is generally behaving as expected and allow us to notice if it is causing any damage to the wikis. Each leading indicator comes with a plan of action in case the defined threshold is reached, so that the team knows what to do.
| Indicator | Plan de acción |
|---|---|
| Revert rate | This suggests that the community finds the "add an image" edits to be unconstructive. If the revert rate for "add an image" is substantially higher than that of unstructured tasks, we will analyze the reverts in order to understand what causes this increase, then adjust the task in order to reduce the likelihood of edits being reverted. |
| User rejection rate | This can indicate that we are suggesting a lot of images that are not good matches. If the rejection rate is above 40%, we will QA the image suggestion algorithm and adjust thresholds or make changes to improve the quality of the recommendations. |
| Over-acceptance rate | This might indicate that some users aren't actually applying judgment to their tasks, meaning we might want to implement different quality gates. (What percentage of users who have a complete session have never rejected or skipped an image? What percentage of users who have five or more complete sessions have never rejected or skipped an image? How many sessions across all users contained only acceptances?) |
| Task completion rate | This might indicate that there’s an issue with the editing workflow. If the proportion of users who start the "add an image" task and complete it is lower than 55% (completion rate for "add a link"), we investigate where in the workflow users leave and deploy design changes to enable them to continue. |
We collected data on usage of "add an image" from deployment on November 29, 2021 until December 14, 2021. "Add an image" has only been made available on the mobile website, and is given to a random 50% of registrations on that platform (excluding our 20% overall control group). We therefore focus on mobile users registered after deployment. This dataset excluded known test accounts, and does not contain data from users who block event logging (e.g. through their ad blocker).
Overall: The most notable thing about the leading indicator data is how few edits have been completed so far: only 89 edits over the first two weeks. Over the first two weeks of "add a link", almost 300 edits were made. That feature was deployed to both desktop and mobile users, but that alone is not enough to make up the difference. The leading indicators below give some clues. For instance, task completion rate is notably low. We also notice that people do not do many of these tasks in a row, whereas with "add a link", users do dozens in a row. This is a prime area for future investigation.
Tasa de reversiones: We use edit tags to identify edits and reverts, and reverts have to be done within 48 hours of the edit. The latter is in line with common practices for reverts.
| Tipo de edición | N ediciones | N reversiones | Tasa de reversión |
|---|---|---|---|
| Añadir una imagen | 69 | 13 | 18,8% |
| Añadir un enlace | 209 | 4 | 1,9% |
| Revisión | 93 | 19 | 20,4% |
The "add an image" revert rate is comparable to the copyedit revert rate, and it’s significantly higher than "add a link" (using a test of proportions). Because "add an image" has a comparable revert rate to unstructured tasks, the threshold described in the leading indicator table is not met, and we do not have cause for alarm. That said, we are still looking into why reverts are occurring in order to make improvements. One issue we've noticed so far is a large number of users saving edits from outside the "add an image" workflow. They can do this by toggling to the visual editor, but it is happening so much more often than for "add a link" that we think there is something confusing about the "caption" step that is causing users to wander outside of it.
Tasa de rechazo: We define an edit “session” as reaching the edit summary dialogue or the skip dialogue, at which point we count whether the recommended image was accepted, rejected, or skipped. Users can reach this dialogue multiple times, because we think that choosing to go back and review an image or edit the caption is a reasonable choice.
| N aceptadas | % | N rechazadas | % | N saltadas | % | N total |
|---|---|---|---|---|---|---|
| 53 | 41,7 | 38 | 29,9 | 36 | 28,3 | 127 |
The threshold in the leading indicator table was a rejection rate of 40%, and this threshold has not been met. This means that users are rejecting suggestions at about the same rate as we expected, and we don't have reason to believe the algorithm is underperforming.
Over-acceptance rate: We reuse the concept of an "edit session" from the rejection rate analysis, and count the number of users who only have sessions where they accepted the image. In order to understand whether these users make many edits, we measure this for all users as well as for those with multiple edit sessions and five or more edit sessions. In the table below, the "N total" column shows the total number of users with that number of edit sessions, and "N accepted all" the number of users who only have edit sessions where they accepted all suggested images.
| Ediciones | N total | N aceptadas en total | % |
|---|---|---|---|
| ≥1 edición | 97 | 34 | 35,1 |
| ≥2 edits | 21 | 8 | 38,1 |
| ≥5 ediciones | 0 | 0 | 0,0 |
It is clear that over-acceptance is not an issue in this dataset, because there are no users who have 5 or more completed image edits, and for those who have more than one, 38% of the users accepted all their suggestions. This is in the expected range, given that the algorithm is expected usually to make good suggestions.
Task completion rate: We define "starting a task" as having an impression of "machine suggestions mode". In other words, the user is loading the editor with an "add an image" task. Completing a task is defined as clicking to save the edit, or confirming that you skipped the suggested image.
| N Started a Task | N Completed 1+ Tasks | % |
|---|---|---|
| 313 | 96 | 30,7 |
The threshold defined in the leading indicator table is "lower than 55%", and this threshold has been met. This means we are concerned about why users do not make their way through the whole workflow, and we want to understand where they get stuck or drop out.
Add an Image Experiment Analysis
Review the full report: "Add an Image" Experiment Analysis, March 2024.
"Añadir una imagen" a una sección

En las wikis en las que está implementado, las personas recién llegadas tienen acceso a la tarea estructurada "añadir una imagen" desde su página de inicio. La tarea existente "añadir una imagen" sugiere imágenes a nivel de artículo para artículos sin ilustraciones. A continuación, la imagen se añade a la sección principal del artículo para ayudar a ilustrar el concepto del artículo en su conjunto.

Habrá una introducción a la tarea, seguida de una sugerencia específica (que incluye la razón por la que se sugiere la imagen). Si la persona recién llegada decide que la imagen encaja en la sección del artículo, entonces recibe orientación sobre la redacción del pie de imagen. La tarea estructurada proporciona detalles de la imagen, ayuda adicional para la redacción del pie de imagen si es necesario y, a continuación, solicita que se revise y publique la edición.
A partnership with the Structured Data team
Este es uno de los aspectos del proyecto Datos estructurados en toda Wikipedia. Esta nueva tarea proporcionará sugerencias de imágenes que sean relevantes para una sección concreta dentro de un artículo. Esta tarea de sugerencia de imágenes a nivel de sección se considerará una tarea más compleja que sólo se sugerirá a las personas recién llegadas que tengan éxito en la actual tarea "añadir una imagen" a nivel de artículo.
Lea más sobre el trabajo del equipo de Datos Estructurados en Wikimedia aquí: Sugerencias de imágenes a nivel de sección.
Hipótesis
- Una experiencia de edición estructurada reducirá la barrera de entrada y, por tanto, atraerá a más personas y a más tipos de usuarios que una experiencia no estructurada.
- Quienes se familiaricen con el flujo de trabajo realizarán más ediciones en su primera sesión y es más probable que vuelvan para realizar más.
- La adición de un nuevo tipo de tarea "añadir una imagen" aumentará el número de sugerencias de imágenes disponibles para cada idioma.
Ámbito
Entrega clave: finalización de las Imágenes a nivel de sección (tarea estructurada para personas nuevas) Épica (1 $).
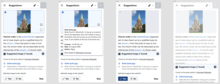
Diseño
A la derecha se pueden ver capturas de pantalla de dos diseños de móvil. Los diseños de "añadir una imagen a nivel de sección" son visibles en este archivo Figma.
Test de usuario
Las pruebas iniciales con usuarios/as de los diseños se completaron en abril de 2023 en inglés. Se dieron instrucciones a seis personas testeadoras, a quienes se pidió que experimentaran con este prototipo de diseño a nivel de sección y evaluaran la facilidad y el agrado de la tarea. La edad de los participantes oscilaba entre los 18 y los 55 años, procedían de 5 países diferentes y la mayoría no había editado Wikipedia anteriormente. 3 de las personas del test eran hombres y otras 3 eran mujeres. Se les pidió que revisaran dos sugerencias de imágenes, una era una "buena" sugerencia de imagen y la otra era una "mala" sugerencia de imagen.
Algunas conclusiones clave de las pruebas de usuarios:
- Todos los participantes entendieron el onboarding: "'Claro, fácil de entender, directo'".
- Los participantes parecían comprender la tarea y que debían centrarse en la sección a la hora de tomar su decisión. Un participante aceptó una sugerencia de imagen "mala":
- 2/6 participantes aceptaron la sugerencia de imagen "buena" (3 rechazaron la imagen, 1 participante la omitió).
- 5/6 participantes rechazaron la sugerencia de imagen "mala".
- Nota: el algoritmo que potencia las sugerencias de imágenes debería proporcionar más sugerencias "buenas" que "malas", pero el algoritmo no es perfecto, por lo que esta tarea necesita revisión humana y es adecuada para las personas que empiezan a editar.
- Algunos participantes mencionaron que querían revisar más de una imagen por sección: “Una sugerencia no es suficiente, tal vez pueda presentar más imágenes entre las que elegir para que pueda seleccionar la imagen más adecuada.”
Evaluación del algoritmo
El equipo de Crecimiento pretende garantizar que las tareas estructuradas para las personas nuevas ofrezcan sugerencias acertadas al menos el 70% de las veces. Hemos realizado varias rondas de evaluación para revisar la precisión del algoritmo de sugerencia de imágenes.
En una evaluación inicial, las sugerencias fueron claramente imprecisas (T316151). Se sugirieron muchas imágenes en secciones que no deberían tener imágenes, o la imagen estaba relacionada con un tema de la sección pero no representaba a la sección en su conjunto. Basándose en los resultados de esta evaluación, el equipo de Datos Estructurados siguió trabajando en mejoras lógicas y de filtrado para garantizar que las sugerencias fueran más precisas (1 $).
En la segunda evaluación, por término medio, las sugerencias fueron mucho mejores (T330784). Por supuesto, los resultados variaron mucho según el idioma, pero la precisión media fue bastante alta en muchas wikis. Sin embargo, hay algunas wikis en las que las sugerencias siguen sin ser lo suficientemente buenas como para presentarlas a las personas novatas, a menos que sólo utilicemos las sugerencias de "buena intersección". Eso limitaría mucho el número de sugerencias de imágenes disponibles, por lo que en su lugar estamos intentando aumentar la puntuación de confianza de las sugerencias que ofrecemos.
| wiki | % buen alineamiento | % buena intersección | % buena imagen p18/p373/plomo | total de sugerencias valoradas |
|---|---|---|---|---|
| arwiki | 71 | 91 | 54 | 511 |
| bnwiki | 28 | 86 | 26 | 204 |
| cswiki | 41 | 77 | 23 | 128 |
| enwiki | 76 | 96 | 75 | 75 |
| eswiki | 60 | 67 | 48 | 549 |
| frwiki | N.A. | N.A. | 100 | 3 |
| idwiki | 66 | 81 | 37 | 315 |
| ptwiki | 92 | 100 | 84 | 85 |
| ruwiki | 73 | 89 | 69 | 250 |
| overall | 64 | 86 | 57 | 2,120 |
Es importante tener en cuenta que esta tarea será configurable por la Comunidad a través de Special:EditGrowthConfig. Esperamos mejorar la tarea hasta el punto de que pueda funcionar bien en todas las wikis, pero las comunidades decidirán en última instancia si esta tarea es una buena opción y debe permanecer habilitada.
Consulta a la comunidad
Para mayo de 2023 está previsto un debate con las wikis piloto de Crecimiento (T332530). Publicaremos diseños, planes y preguntas en la Wikipedia en árabe, Wikipedia en bengalí, Wikipedia en checo y Wikipedia en español, además de compartir más detalles aquí en MediaWiki.
Medición
We decided to not deploy this feature in an A/B test and instead allow users to opt in to using it through the task selection dialogue on the Newcomer Homepage, or through the "Try a new task" post-edit dialogue that's part of the Levelling Up features. This meant that we focused on measuring a set of leading indicators to understand if the task was performing well. More details about this can be found in T332344.
We pulled data from Growth's KPI Grafana board from 2023-07-31 to 2023-08-28 (available here) for Section-Level and Article-Level suggestions. This timeframe was chosen because it should not be as much affected by the June/July slump in activity that we often see on the wikis. The end date is limited by the team shutting off image suggestions in late August (see T345188 for more information). This data range covers four whole weeks of data. While this dataset does not allow us to separate it by platform (desktop and mobile web), nor does it allow us more fine-grained user filtering, it was easily available and provides us with a reasonably good picture that's sufficient for this kind of analysis at this time. Using this dataset we get the overview of task activity shown in Table 1.
| Task type | Task clicks | Saved edits | Reverts | Task completion rate | Revert rate |
|---|---|---|---|---|---|
| Section-level | 1149 | 688 | 60 | 58,1% | 9,0% |
| Article-level | 6800 | 2414 | 105 | 35,5% | 4,3% |
We see from the table that the task completion rate for section-level image suggestions is high, on par with Add a Link (ref) when that was released. This is likely because the section-level task is something users either choose themselves in the task selection dialogue, or choose to try out after being asked through the "Try a new task" dialogue that's part of Levelling Up. Those users are therefore likely already experienced editors and don't have too many issues with completing this task.
The revert rate for the section-level task is higher than the article-level task. We don't think this difference is cause for concern for two reasons. First, it might be harder to agree that an article is clearly improved by adding a section-level image compared to adding an article-level image. Secondly, articles suggested for section-level images already have a lead image, which might mean that they're also longer and have more contributors scrutinizing the edit.