Growth/Personalized first day/Structured tasks/Add an image
This page describes work on an "add an image" structured task, which is a type of structured task that the Growth team will offer through the newcomer homepage.
|
Add an image
Suggest images from Commons that newcomers could add to Wikipedia articles
|

This page contains major assets, designs, open questions, and decisions.
This project in a nutshell:
|
Most incremental updates on progress will be posted on the general Growth team updates page, with some large or detailed updates posted here.
Current status
edit- 2020-06-22: initial thinking about ideas to create a simple algorithm to recommend images
- 2020-09-08: evaluated a first attempt at a matching algorithm in English, French, Arabic, Korean, Czech, Vietnamese
- 2020-09-30: evaluated a second attempt at a matching algorithm in English, French, Arabic, Korean, Czech, Vietnamese
- 2020-10-26: internal engineering discussion of possible feasibility for image recommendation service
- 2020-12-15: running initial round of user tests to start to understand whether newcomers might succeed at this task
- 2021-01-20: Platform Engineering team begins building proof-of-concept API for image recommendations
- 2021-01-21: Android team begins work on minimum viable version for learning purposes
- 2021-01-28: posted user test results
- 2021-02-04: posted summary of community discussion and coverage statistics
- 2021-05-07: Android MVP is released to users
- 2021-08-06: posted results from Android and mockups for Iteration 1
- 2021-08-17: backend work begins on Iteration 1
- 2021-08-23: posted interactive prototypes and began user tests in English and Spanish
- 2021-10-07: posted findings from user tests and final designs based on the findings
- 2021-11-19: ambassador begin testing the feature in their production Wikipedias
- 2021-11-22: image suggestion dataset is refreshed in advance of releasing Iteration 1 to users
- 2021-11-29: Iteration 1 deployed to 40% of mobile accounts on Arabic, Czech, and Bengali Wikipedias.
- 2021-12-22: posted leading indicators
- 2022-01-28: desktop version deployed for 40% of new accounts on Arabic, Czech, and Bengali Wikipedias.
- 2022-02-16: Spanish Wikipedia newcomers start getting "add an image"
- 2022-03-22: Portuguese, Farsi, French and Turkish Wikipedia newcomers start getting "add an image"
- 2023-02-07: Complete evaluation of section-level image suggestions (T316151)
- 2023-10-16: Image Recommendations added to the Android Wikipedia app
- 2024-04-11: Publish "Add an image" Experiment Analysis
- Next: Release "Add an image" to more Wikipedias
Summary
editStructured tasks are meant to break down editing tasks into step-by-step workflows that make sense for newcomers and make sense on mobile devices. The Growth team believes that introducing these new kinds of editing workflows will allow more new people to begin participating on Wikipedia, some of whom will learn to do more substantial edits and get involved with their communities. After discussing the idea of structured tasks with communities, we decided to build the first structured task: "add a link".
After deploying "add a link" in May 2021, we collected initial data showing that the task was engaging to newcomers and that they were making edits with low revert rates -- indicating that structured tasks seem valuable for the newcomer experience and the wikis.
Even as we built that first task, we have been thinking about what a next structured task could be, and we think that adding images could be a good fit for newcomers. The idea is that a simple algorithm would recommend images from Commons to be placed on articles that have no images. To start with, it would use only existing connections that can be found in Wikidata, and newcomers would use their judgment to place the image on the article or not.
We know that there are many open questions around how this would work, and many potential reasons that it might not go right. That's why we are hoping to hear from lots of community members and have an ongoing discussion as we decide how to proceed.
Related projects
editThe Android team has worked on a similar Image Recommendations task for the Wikipedia Android app using the same underlying components. Additionally, the Structured Data team has released image recommendations notifications targeted at more experienced users and benefiting from Structured Data on Commons.
Why images?
edit| Expand to read the "Why images?" section |
|---|
|
Looking for substantial contributions When we first discussed structured tasks with community members, many pointed out that adding wikilinks is not a particularly high-value type of edit. Community members brought up ideas for how newcomers could make more substantial contributions. One idea is images. Wikimedia Commons contains 65 million images, but in many Wikipedias, over 50% of articles have no images. We believe that many images from Commons can make Wikipedia substantially more illustrated. Interest from newcomers We know that many newcomers are interested in adding images to Wikipedia. "To add an image" is a common response newcomers give on the welcome survey for why they are creating their account. We also see that one of the most frequent help panel questions is about how to add images, true across all the wikis we work with. Though most of these newcomers are probably bringing their own image that they want to add, this hints at how images can be engaging and exciting. That makes sense, given the image-heavy elements of the other platforms that newcomers participate in -- things like Instagram and Facebook. Difficulty of working with images The many help panel questions about images reflects that the process to add them to articles is too difficult. Newcomers have to understand the difference between Wikipedia and Commons, rules around copyright, and the technical parts of inserting and captioning the image in the right place. Finding an image in Commons for an unillustrated article requires even more skills, such as knowledge of Wikidata and categories. Success of "Wikipedia Pages Wanting Photos" campaign The Wikipedia Pages Wanting Photos campaign (WPWP) was a surprising success: 600 users added images to 85,000 pages. They did this with the assistance of a couple of community tools that identified pages that have no images, and which suggest possible images through Wikidata. While there are important lessons to be learned about how to help newcomers succeed with adding images, this gives us confidence that users can be enthusiastic about adding images and that they can be assisted by tools. Taking this all together Thinking about all this information together, we think that it could be possible to build an "add an image" structured task that is both fun for newcomers and productive for Wikipedias. |
Idea validation
editFrom June 2020 through July 2021, the Growth team worked on community discussions, background research, evaluations, and proof-of-concepts around the "add an image" task. This led to the decision to start building our first iteration in August 2021 (see Iteration 1). This section contains all that background work leading up to Iteration 1.
| Expand to read the "Idea validation" section | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
AlgorithmeditOur ability to make a structured task for adding images depends on whether we can create an algorithm that generates sufficiently good recommendations. We definitely do not want to urge newcomers to add the wrong images to articles, which would cause work for patrollers to clean up after them. Therefore, trying to see if we could make a good algorithm is one of the first things we've worked on. LogiceditWe have been working with the Wikimedia Research team, and so far we have been testing an algorithm that prioritizes accuracy and human judgment. Rather than using any computer vision, which can generate unexpected results, it simply aggregates existing information in Wikidata, drawing on connections made by experienced contributors. These are the three main ways that it suggests matches to unillustrated articles:
The algorithm also includes logic to do things like exclude images that are likely icons or that are present on an article as part of a navbox. AccuracyeditAs of August 2021, we've gone through three rounds of testing the algorithm, each time looking at matches to articles in six languages: English, French, Arabic, Vietnamese, Czech, and Korean. The evaluations were done by our team's ambassadors and other expert Wikimedians, who are native speakers in the languages being tested. First two evaluations Looking at 50 suggested matches in each language, we went through and classified them into these groups:
A question that runs throughout the work on an algorithm like this is: how accurate does it need to be? If 75% of matches are good is that enough? Does it need to be 90% accurate? Or could it be as low as 50% accurate? This depends on how good the judgment is of the newcomers using it, and how much patience they have for weak matches. We'll learn more about this when we user test the algorithm with real newcomers. In the first evaluation, the most important thing is that we found a lot of easy improvements to make to the algorithm, including types of articles and images to exclude. Even without those improvements, about 20-40% of matches were "2s", meaning great matches for the article (depending on the wiki). You can see the full results and notes from the first evaluation here. For the second evaluation, many improvements were incorporated, and the accuracy increased. Between 50-70% of matches were "2s" (depending on the wiki). But increasing the accuracy can decrease the coverage, i.e. the number of articles for which we can make matches. Using conservative criteria, the algorithm may only be able to suggest tens of thousands of matches in a given wiki, even if that wikis has hundreds of thousands or millions of articles. We believe that that kind of volume would be sufficient to build an initial version of this feature. You can see the full results and notes from the second evaluation here. Third evaluation In May 2021, the Structured Data team conducted a much larger-scale test of the image matching algorithm (and the MediaSearch algorithm) in Arabic, Cebuano, English, Vietnamese, Bengali, and Czech Wikipedias. In this test, about 500 matches from both the image matching algorithm and MediaSearch were evaluated by experts in each language, who good could classify them as "Good", "Okay", or "Bad" matches. The results detailed below show these things:
The full dataset of results can be found here. CoverageeditThe accuracy of the algorithm is clearly a very important component. Equally important is its "coverage" -- this refers to how many image matches it can make. Accuracy and coverage tend to be inversely related: the more accurate an algorithm, the fewer suggestions it will make (because it is only making suggestions when it is confident). We need to answer these questions: is the algorithm able to provide enough matches that it is worthwhile to build a feature with it? Would it be able to make a substantial impact on wikis? We looked at 22 Wikipedias to get a sense of the answers. The table is below these summary points:
MediaSearcheditAs mentioned above, the Structured Data team is exploring using the MediaSearch algorithm to increase coverage and yield more candidate matches. MediaSearch works by combining traditional text-based search and structured data to provide relevant results for searches in a language-agnostic way. By using the Wikidata statements added to images as part of Structured Data on Commons as a search ranking input, MediaSearch is able to take advantage of aliases, related concepts, and labels in multiple languages to increase the relevance of image matches. You can find more information about how MediaSearch works. As of February 2021, team is currently experimenting with how to provide a confidence score for MediaSearch matches that the image recommendations algorithm can consume and use to determine whether a match from MediaSearch is of sufficient quality to use in image matching tasks. We want to be sure that users are confident in the recommendations that MediaSearch provides before incorporating them into the feature. The Structured Data team is also exploring and prototyping a way for user generated bots to use the results generated by both the image recommendations algorithm and MediaSearch to automatically add images to articles. This will be an experiment in bot-heavy wikis, in partnership with community bot writers. You can learn more about that effort or express interest in participating in the Phabricator task. In May 2021, in the same evaluation cited in the "Accuracy" section above, MediaSearch was found to be far less accurate than the image matching algorithm. Where the image matching algorithm was about 78% accurate, matches from MediaSearch were about 38% accurate. Therefore, the Growth team is not planning to use MediaSearch in its first iteration of the "add an image" task. Questions and discussioneditOpen questionseditImages are such an important and visible part of the Wikipedia experience. It is critical that we think hard about how a feature enabling the easy adding of images would work, what the potential pitfalls might be, and what the implications would be for community members. To that end, we have many open questions, and we want to hear of more that community members can bring up.
Notes from community discussions 2021-02-04editStarting in December 2020, we invited community members to talk about the "add an image" idea in five languages (English, Bengali, Arabic, Vietnamese, Czech). The English discussion mostly took place on the discussion page here, with local language conversations on the other four Wikipedias. We heard from 28 community members, and this section summarizes some of the most common and interesting thoughts. These discussions are heavily influencing our next set of designs.
Plan for user testingedit Thinking about the open questions above, in addition to community input, we want to generate some quantitative and qualitative information to help us evaluate the feasibility of building an "add an image" feature. Though we have been evaluating the algorithm amongst staff and Wikimedians, it is important to see how newcomers react to it, and to see how they use their judgment when deciding on whether an image belongs in an article. To that end, we are going to run tests with usertesting.com, in which people new to Wikipedia editing can go through potential image matches in a prototype and respond "Yes", "No", or "Unsure". We built a quick prototype for the test, backed with real matches from the current algorithm. The prototype just shows one match after another, all in a feed. The images are shown along with all the relevant metadata from Commons:
Though this may not be what the workflow would be like for real users in the future, the prototype was made so that testers could go through lots of potential matches quickly, generating lots of information. To try out the interactive prototype, use this link. Note that this prototype is primarily for viewing the matches from the algorithm -- we have not yet thought hard about the actual user experience. It does not actually create any edits. It contains 60 real matches proposed by the algorithm. Here's what we'll be looking for in the test:
DesigneditConcept A vs. BeditIn thinking about design for this task, we have a similar question as we faced for "add a link" with respect to Concept A and Concept B. In Concept A, users would complete the edit at the article, while in Concept B, they would do many edits in a row all from a feed. Concept A gives the user more context for the article and editing, while Concept B prioritizes efficiency. In the interactive prototype above, we used Concept B, in which the users proceed through a feed of suggestions. We did that because in our user tests we wanted to see many examples of users interacting with suggestions. That's the sort of design that might work best for a platform like the Wikipedia Android app. For the Growth team's context, we're thinking more along the lines of Concept A, in which the user does the edit at the article. That's the direction we chose for "add a link", and we think that it could be appropriate for "add an image" for the same reasons. Single vs. MultipleeditAnother important design question is whether to show the user a single proposed image match, or give them multiple images matches to choose from. When giving multiple matches, there's a greater chance that one of the matches is a good one. But it also may make users think they should choose one of them, even if none of them are good. It will also be a more complicated experience to design and build, especially for mobile devices. We have mocked up three potential workflows:
   User tests December 2020editBackground During December 2020, we used usertesting.com to conduct 15 tests of the mobile interactive prototype. The prototype contained only a rudimentary design, little context or onboarding, and was tested only in English with users who had little or no previous Wikipedia editing experience. We deliberately tested a rudimentary design earlier in the process so that we could gather lots of learnings. The primary questions we wanted to address with this test were around feasibility of the feature as a whole, not around the finer points of design:
In the test, we asked participants to annotate at least 20 article-image matches while talking out loud. When they tapped yes, the prototype asked them to write a caption to go along with the image in the article. Overall, we gathered 399 annotations. Summary We think that these user tests confirm that we could successfully build an "add an image" feature, but it will only work if we design it right. Many of the testers understood the task well, took it seriously, and made good decisions -- this gives us confidence that this is an idea worth pursuing. On the other hand, many other users were confused about the point of the task, did not evaluate as critically, and made weak decisions -- but for those confused users, it was easy for us to see ways to improve the design to give them the appropriate context and convey the seriousness of the task. Observations To see the full set of findings, feel free to browse the slides. The most important points are written below the slides. 
Metrics
Takeaways
MetadataeditThe user tests showed us that image metadata from Commons (e.g. filename, description, caption, etc.) is critical for a user to confidently make a match. For instance, though the user can see that the article is about a church, and that the photo is of a church, the metadata allowed them to tell if it is the church discussed in the article. In the user tests, we saw that these items of metadata were most important: filename, description, caption, categories. Items that were not useful included size, upload date, and uploading username. Given that metadata is a critical part of making a strong decision, we have been thinking about whether users will need to be have metadata in their own language in order to do this task, especially in light of the fact that the majority of Commons metadata is in English. For 22 wikis, we looked at the percentage of the image matches from the algorithm that have metadata elements in the local language. In other words, for the images that can be matched to unillustrated articles in Arabic Wikipedia, how many of them have Arabic descriptions, captions, and depicts? The table is below these summary points:
Given that local-language metadata has low coverage, our current idea is to offer the image matching task to just those users who can read English, which we could ask the user as a quick question before beginning the task. This unfortunately limits how many users could participate. It's a similar situation to the Content Translation tool, in that users need to know the language of the source wiki and the destination wiki in order to move content from one wiki to another. We also believe there will be sufficient numbers of these users based on results from the Growth team's welcome survey, which asks newcomers which languages they know. Depending on the wiki, between 20% and 50% of newcomers select English. Android MVPeditSee this page for the details on the Android MVP. BackgroundeditAfter lots of community discussion, many internal discussions, and the user test results from above, we believe that this "add an image" idea has enough potential to continue to pursue. Community members have been generally positive, but also cautionary -- we also know that there are still many concerns and reasons the idea might not work as expected. The next step we want to in order to learn more is to build a "minimum viable product" (MVP) for the Wikipedia Android app. The most important thing about this MVP is that it will not save any edits to Wikipedia. Rather, it will only be used to gather data, improve our algorithm, and improve our design. The Android app is where "suggested edits" originated, and that team has a framework to build new task types easily. These are the main pieces:
ResultseditThe Android team released the app in May 2021, and over several weeks, thousands of users evaluated tens of thousands of image matches from the image matching algorithm. The resulting data allowed the Growth team to decide to proceed with Iteration 1 of the "add an image" task. In looking at the data, we were trying to answer two important questions around "Engagement" and "Efficacy". Engagement: do users of all languages like this task and want to do it?
Efficacy: will resulting edits be of sufficient quality?
See the full results are here. EngineeringeditThis section contains links on how to follow along with technical aspects of this project: |
Iteration 1
editIn July 2021, the Growth team decided to move forward with building a first iteration of an "add an image" task for the web. This was a difficult decision, because of the many open questions and risks around encouraging newcomers to add images to Wikipedia articles. But after going through a year of idea validation, and looking through the resulting community discussions, evaluations, tests, and proofs-of-concepts around this idea, we decided to build a first iteration so that we could continue learning. These are the main findings from the idea validation phase that led us to move forward:
- Cautious community support: community members are cautiously optimistic about this task, agreeing that it would be valuable, but pointing out many risks and pitfalls that we think we can address with good design.
- Accurate algorithm: the image matching algorithm has shown to be 65-80% accurate through multiple different tests, and we have been able to refine it over time.
- User tests: many newcomers who experienced prototypes found the task fun and engaging.
- Android MVP: the results from the Android MVP showed that newcomers generally applied good judgment to the suggestions, but more importantly, gave us clues about how to improve their results in our designs. The results also hinted that the task could work well across languages.
- Overall learnings: having bumped into many pitfalls through our various validation steps, we'll be able to guard against them in our upcoming designs. This background work has given us lots of ideas on how to lead newcomers to good judgment, and how to avoid damaging edits.
Hypotheses
editWe're not certain that this task will work well -- that's why we plan to build it in small iterations, learning along the way. We do think that we can make a good attempt using our learnings so far to build a lightweight first iteration. One way to think about what we're doing with our iterations is hypothesis testing. Below are five optimistic hypotheses we have about the "add an image" task. Our aim in Iteration 1 will be to see if these hypotheses are correct.
- Captions: users can write satisfactory captions. This is our biggest open question, since images that get placed into Wikipedia articles generally require captions, but the Android MVP did not test the ability of newcomers to write them well.
- Efficacy: newcomers will have strong enough judgment that their edits will be accepted by the communities.
- Engagement: users like to do this task on mobile, do many, and return to do more.
- Languages: users who don’t know English will be able to do this task. This is an important question, since the majority of metadata on Commons is in English, and it is critical for users to read the filename, description, and caption from Commons in order to confidently confirm a match.
- Paradigm: the design paradigm we built for "the add a link structured task" will extend to images.
Scope
editBecause our main objective with Iteration 1 is learning, we want to get an experience in front of users as soon as we can. This means we want to limit the scope of what we build so that we can release it quickly. Below are the most important scope limitations we think we should impose on Iteration 1.
- Mobile only: while many experienced Wikimedians do most of the wiki work from their desktop/laptop, the newcomers who are struggling to contribute to Wikipedia are largely using mobile devices, and they are the more important audience for the Growth team's work. If we build Iteration 1 only for mobile, we'll concentrate on that audience while saving the time it would take to additionally design and build the same workflow for desktop/laptop.
- Static suggestions: rather than building a backend service to continuously run and update the available image matches using the image matching algorithm, we'll run the algorithm once and use the static set of suggestions for Iteration 1. While this won't make the newest images and freshest data available, we think it will be sufficient for our learning.
- Add a link paradigm: our design will generally follow the same patterns as the design for our previous structured task, "add a link".
- Unillustrated articles: we'll limit our suggestions only to articles that have no illustrations in them at all, as opposed to including articles that have some already, but could use more. This will mean that our workflow will not need to include steps for the newcomer to choose where in the article to place the image. Since it will be the only image, it can be assumed to be the lead image at the top of the article.
- No infoboxes: we'll limit our suggestions only to articles that have no infoboxes. That's because if an unillustrated article has an infobox, its first image should usually be placed in the infobox. But it is a major technical challenge to make sure we can identify the correct image and image caption fields in all infoboxes in many languages. This also avoids articles that have Wikidata infoboxes.
- Single image: although the image matching algorithm can propose multiple image candidates for a single unillustrated article, we'll limit Iteration 1 to only proposing the highest-confidence candidate. This will make for a simpler experience for the newcomer, and for a simpler design and engineering effort for the team.
- Quality gates: we think we should include some sort of automatic mechanism to stop a user from making a large number of bad edits in a short time. Ideas around this include (a) limiting users to a certain number of "add an image" edits per day, (b) giving users additional instructions if they spend too little time on each suggestions, (c) giving users additional instructions if they seem are accepting too many images. This idea was inspired by English Wikipedia's 2021 experience with the Wikipedia Pages Wanting Photos campaign.
- Pilot wikis: as with all new Growth developments, we will deploy first only to our four pilot wikis, which are Arabic, Vietnamese, Bengali, and Czech Wikipedias. These are communities who follow along with the Growth work closely and are aware that they are part of experiments. The Growth team employs community ambassadors to help us correspond quickly with those communities. We may add Spanish and Portuguese Wikipedias to the list in the coming year.
We're interested to hear community members' opinions on if these scoping choices sound good, or if any sound like they would greatly limit our learnings in Iteration 1.
Design
edit
Mockups and prototypes
editBuilding on designs from our previous user tests and on the Android MVP, we are considering multiple design concepts for Iteration 1. For each of five parts of the user flow, we have two alternatives. We'll user test both to gain information from newcomers. Our user tests will take place in English and Spanish -- our team's first time testing in a non-English language. We also hope community members can consider the designs and provide their thoughts on the talk page.
Prototypes for user testing
The easiest way to experience what we're considering to build is through the interactive prototypes. We've built prototypes for both the "Concept A" and "Concept B" designs, and they are available in both English and Spanish. These are not actual wiki software, but rather a simulation of it. That means that no edits are actually saved, and not all the buttons and interactions work -- but the most important ones relevant to the "add an image" project do work.
Mockups for user testing
Below are static images of the mockups that we're using for user testing in August 2021. Community members are welcome to explore the Growth team designer's Figma file, which contains the mockups below in the lower right of the canvas, as well as the various pieces of inspiration and notes that led to them.
Feed
These designs refer to the very first part of the workflow, in which the user chooses an article to work on from the suggested edits feed. We want the card to be attractive, but also not confuse the user.
-
 Concept A: contains obscured thumbnail of suggested image, giving the user some visuals about the upcoming task.
Concept A: contains obscured thumbnail of suggested image, giving the user some visuals about the upcoming task. -
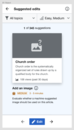 Concept B: no thumbnail of image, so that the user doesn't start to falsely feel like the proposed image "belongs" with the article.
Concept B: no thumbnail of image, so that the user doesn't start to falsely feel like the proposed image "belongs" with the article.


Onboarding
These designs refer to what the user sees after opening up their first task, meant to explain what the task is and how to do a good job. We want the user to understand that adding an image is a consequential edit that needs to be considered seriously. Note that this exact text has not been designed carefully yet -- rather, we are thinking now about the experience through which we deliver this content.
-
 Concept A: full screen overlays explaining the concepts and steps of adding an image.
Concept A: full screen overlays explaining the concepts and steps of adding an image. -
 Concept B: sequential popups pointing to the elements for the different parts of the workflow.
Concept B: sequential popups pointing to the elements for the different parts of the workflow.


Adding the image
These designs refer to the part of the workflow in which the user sees the suggested image, views its metadata from Commons, and decides whether to add it to the article. We know from user tests that it is important for the user to read the image title, Commons description, and Commons caption in order to make this decision correctly. This is a challenging part of the design: making all that information available on the mobile screen.
-
 Concept A: suggested image is shown in place where it will go in the article, giving the user the sense that adding the image will, in fact, put it on the article. User can expand the image to view it fullscreen and tap the "i" to see more metadata.
Concept A: suggested image is shown in place where it will go in the article, giving the user the sense that adding the image will, in fact, put it on the article. User can expand the image to view it fullscreen and tap the "i" to see more metadata. -
 Concept B: suggested image is shown in the "image inspector" card, along with the Commons metadata that goes with the image. User can expand the image to view it fullscreen.
Concept B: suggested image is shown in the "image inspector" card, along with the Commons metadata that goes with the image. User can expand the image to view it fullscreen.


Caption and publish
These designs refer to the part of the workflow after the user has decided to add an image to the article, and is now writing a caption to go with it. This may be the most challenging part for the newcomer, and we are still thinking about how to help them understand what sort of caption is appropriate.
-
 Concept A: caption added via the existing Visual Editor caption dialog on its own screen.
Concept A: caption added via the existing Visual Editor caption dialog on its own screen. -
 Concept B: caption added in place on the article, helping the user understand the context for where the caption will be seen.
Concept B: caption added in place on the article, helping the user understand the context for where the caption will be seen.


Rejection
When a user rejects a suggestion, we want to collect data on why the match was wrong, so that we can improve the algorithm. This is also an opportunity to continually remind the user about the evaluation criteria they should be using as they evaluate images.
-
 Concept A: user can only choose one option.
Concept A: user can only choose one option. -
 Concept B: user can choose multiple options.
Concept B: user can choose multiple options.


User test results September 2021
In August 2021, we ran 32 user tests amongst people who were new to Wikipedia editing, using respondents from usertesting.com. Half the respondents walked through Concept A and half through Concept B. In order to represent more diverse perspectives, this was the first time that the Growth team ran user tests outside of English: 11 respondents took the test in Spanish, all of whom were located outside the United States. This will help us make sure we're building a feature that is valuable and understandable for populations around the world.
Our goals for the testing were to identify which parts of the design concepts worked best, and to surface any other potential improvements. These are our main findings and changes to the designs we plan to make.
- Findings
- Concept B clearly performed better for participants in both English and Spanish tests, particularly:
- Better understanding of the task. In Concept A, users sometimes thought the image was already in the article, because of its preview on the suggested edit card and the preview in the article.
- More careful engagement and consideration of article contents and image metadata when evaluating image suitability to an article. We suspect this is because the article and metadata areas were clearly separated.
- Greater use of image details and article contents during caption composition. The Concept B caption experience shows the full article text.
- Other notes
- Most people misunderstood the task initially as uploading images when they opened the Suggested edits module, regardless of design. But expectation about self-sourcing images was immediately corrected for almost all participants as soon as they opened the task, and overall, Design B evoked better task comprehension and successful image evaluation than Design A.
- Newcomers would benefit from more user education around Commons and use of images on Wikipedia articles in their understanding of the broader editing ecosystem of Wikipedia and its sister projects.
- Users understood the purpose of the caption, and understood that it would be displayed with the image in the Wikipedia article.
- Spanish participants were far more interwiki-attuned than English participants. Potentially explore ways to better cater to multilingual/cross-wiki users.
- Spanish participants needed to translate Commons metadata to themselves in order to write good captions in Spanish.
- The current task requires several different skills, such as image evaluation, caption writing, and translation (for reading Commons metadata from a non-English Wikipedia). There may be benefits and opportunities for separating out this task into multiple tasks in future so that users don't have to have all the skills in order to complete the task.
- Concept B clearly performed better for participants in both English and Spanish tests, particularly:
- Changes
- Do not show a preview of the suggested image on the card in the suggested edits feed.
- The onboarding tooltips worked well to help users understand the task. But they could be overwhelming or cluttering for smaller screens. Though we prefer to implement tooltips, we have decided to implement fullscreen overlays for onboarding in Iteration 1, because tooltips will take a substantially longer time to engineer well. We may implement tooltips in a future iteration.
- Image and image metadata need to be next to each other -- when they are in separate parts of the screen, users become confused.
- Because it is very important that users consider image metadata when making their decision and writing the caption, we need to increase the visibility of the metadata with clearer calls to read it.
- Include simple validation on the free-text caption, such as enforcing a minimum length for captions, or not allowing the filename to be part of the caption.
- Provide samples of good and bad captions in the explanation for the caption step.
- When users reject a suggestion and give the reason for the rejection, some of the reasons should not remove the suggestion from the queue, e.g. "I do not know this topic". Perhaps another user will be able to confidently make the match.
- Example captions: below are three image/article pairings used in the test and the actual captions written by user testers. This gives us a sense of the sorts of captions we can expect from newcomers. They all seem to be generally on the right track, though they range from more like "alt text" to more like captions. There are also a couple that miss the mark.
-
 Article: Edward Edwards (Royal navy officer)
Article: Edward Edwards (Royal navy officer)
"Drawing of the HMS Pandora by Robert Batty"
"The HMS Pandora, of which Admiral Edward Edwards captained in order to catch mutineers."
"An 1831 depiction of the HMS Pandora sinking"
"Royal Navy"
"Illustration of HMS Pandora sinking" -
 Article: Fiesque
Article: Fiesque
"Edouard Lalo, composer of the music of the Fiesque opera"
"Photo of Edouard Lalo, composer of Fiesque"
"Edouard Lalo - 1865"
"Eduard Lalo, around 1865"
These captions were translated from Spanish. -
 Article: Bahaettin Rahmi Bediz
Article: Bahaettin Rahmi Bediz
"A photo of Bahaettin Rahmi Bediz taken on 1st January 1924, pictured with his bicycle"
"Bahaettin Radmi Bediz on 1 January 1924"
"Rahmizadephoto1869"
"Rahnizade Bahaeddin Bediz. in uniform, standing next to a bicycle"



Final designs for Iteration 1
Based on the user test findings above, we created the set of designs that we are implementing for Iteration 1. The best way to explore those designs is here in the Figma file, which always contains the latest version.
Measurement
editLeading indicators
editWhenever we deploy new features, we define a set of "leading indicators" that we will keep track of during the early stages of the experiment. These help us quickly identify if the feature is generally behaving as expected and allow us to notice if it is causing any damage to the wikis. Each leading indicator comes with a plan of action in case the defined threshold is reached, so that the team knows what to do.
| Indicator | Plan of Action |
|---|---|
| Revert rate | This suggests that the community finds the "add an image" edits to be unconstructive. If the revert rate for "add an image" is substantially higher than that of unstructured tasks, we will analyze the reverts in order to understand what causes this increase, then adjust the task in order to reduce the likelihood of edits being reverted. |
| User rejection rate | This can indicate that we are suggesting a lot of images that are not good matches. If the rejection rate is above 40%, we will QA the image suggestion algorithm and adjust thresholds or make changes to improve the quality of the recommendations. |
| Over-acceptance rate | This might indicate that some users aren't actually applying judgment to their tasks, meaning we might want to implement different quality gates. (What percentage of users who have a complete session have never rejected or skipped an image? What percentage of users who have five or more complete sessions have never rejected or skipped an image? How many sessions across all users contained only acceptances?) |
| Task completion rate | This might indicate that there’s an issue with the editing workflow. If the proportion of users who start the "add an image" task and complete it is lower than 55% (completion rate for "add a link"), we investigate where in the workflow users leave and deploy design changes to enable them to continue. |
We collected data on usage of "add an image" from deployment on November 29, 2021 until December 14, 2021. "Add an image" has only been made available on the mobile website, and is given to a random 50% of registrations on that platform (excluding our 20% overall control group). We therefore focus on mobile users registered after deployment. This dataset excluded known test accounts, and does not contain data from users who block event logging (e.g. through their ad blocker).
Overall: The most notable thing about the leading indicator data is how few edits have been completed so far: only 89 edits over the first two weeks. Over the first two weeks of "add a link", almost 300 edits were made. That feature was deployed to both desktop and mobile users, but that alone is not enough to make up the difference. The leading indicators below give some clues. For instance, task completion rate is notably low. We also notice that people do not do many of these tasks in a row, whereas with "add a link", users do dozens in a row. This is a prime area for future investigation.
Revert rate: We use edit tags to identify edits and reverts, and reverts have to be done within 48 hours of the edit. The latter is in line with common practices for reverts.
| Task type | N edits | N reverts | Revert rate |
|---|---|---|---|
| Add an image | 69 | 13 | 18.8% |
| Add a link | 209 | 4 | 1.9% |
| Copyedit | 93 | 19 | 20.4% |
The "add an image" revert rate is comparable to the copyedit revert rate, and it’s significantly higher than "add a link" (using a test of proportions). Because "add an image" has a comparable revert rate to unstructured tasks, the threshold described in the leading indicator table is not met, and we do not have cause for alarm. That said, we are still looking into why reverts are occurring in order to make improvements. One issue we've noticed so far is a large number of users saving edits from outside the "add an image" workflow. They can do this by toggling to the visual editor, but it is happening so much more often than for "add a link" that we think there is something confusing about the "caption" step that is causing users to wander outside of it.
Rejection rate: We define an edit “session” as reaching the edit summary dialogue or the skip dialogue, at which point we count whether the recommended image was accepted, rejected, or skipped. Users can reach this dialogue multiple times, because we think that choosing to go back and review an image or edit the caption is a reasonable choice.
| N accepted | % | N rejected | % | N skipped | % | N total |
|---|---|---|---|---|---|---|
| 53 | 41.7 | 38 | 29.9 | 36 | 28.3 | 127 |
The threshold in the leading indicator table was a rejection rate of 40%, and this threshold has not been met. This means that users are rejecting suggestions at about the same rate as we expected, and we don't have reason to believe the algorithm is underperforming.
Over-acceptance rate: We reuse the concept of an "edit session" from the rejection rate analysis, and count the number of users who only have sessions where they accepted the image. In order to understand whether these users make many edits, we measure this for all users as well as for those with multiple edit sessions and five or more edit sessions. In the table below, the "N total" column shows the total number of users with that number of edit sessions, and "N accepted all" the number of users who only have edit sessions where they accepted all suggested images.
| Edits | N total | N accepted all | % |
|---|---|---|---|
| ≥1 edit | 97 | 34 | 35.1 |
| ≥2 edits | 21 | 8 | 38.1 |
| ≥5 edits | 0 | 0 | 0.0 |
It is clear that over-acceptance is not an issue in this dataset, because there are no users who have 5 or more completed image edits, and for those who have more than one, 38% of the users accepted all their suggestions. This is in the expected range, given that the algorithm is expected usually to make good suggestions.
Task completion rate: We define "starting a task" as having an impression of "machine suggestions mode". In other words, the user is loading the editor with an "add an image" task. Completing a task is defined as clicking to save the edit, or confirming that you skipped the suggested image.
| N Started a Task | N Completed 1+ Tasks | % |
|---|---|---|
| 313 | 96 | 30.7 |
The threshold defined in the leading indicator table is "lower than 55%", and this threshold has been met. This means we are concerned about why users do not make their way through the whole workflow, and we want to understand where they get stuck or drop out.
Add an Image Experiment Analysis
editReview the full report: "Add an Image" Experiment Analysis, March 2024.
"Add an image" to a Section
edit
On wikis where it is deployed, newcomers have access to the “add an image” structured task from their Newcomer homepage. The existing "add an image" task suggests article-level image suggestions for entirely unillustrated articles. The image is then added to the article's lead section to help illustrate the article's concept as a whole.

There will be onboarding for the task, followed by a specific suggestion (that includes the reason why the image is suggested). If the newcomer decides the image is a good fit for the article's section, then they receive guidance on caption writing. The structured task provides image details, further caption writing help if needed, and then prompts the newcomer to review and publish the edit.
A partnership with the Structured Data team
This is one aspect of the Structured Data Across Wikipedia project. This new task will provide image suggestions that are relevant to a particular section within an article. This section-level image suggestion task will be considered a more difficult task that will only be suggested to newcomers who are successful at the current article-level “add an image” task.
Read more about the Structured Data Across Wikimedia team’s work here: Section-level image suggestions.Hypotheses
edit- Structured editing experience will lower the barrier to entry and thereby engage more newcomers, and more kinds of newcomers than an unstructured experience.
- Newcomers with the workflow will complete more edits in their first session, and be more likely to return to complete more.
- Adding a new type of “add an image” task will increase the number of image suggestions available for each language.
Scope
editKey deliverable: completion of the Section-Level Images (newcomer structured task) Epic (T321754).
Design
editScreenshots from two mobile designs can be seen on the right. Section-level "add an image" designs are visible in this Figma file.
User testing
editInitial user testing of designs was completed in April 2023 in English. Six testers were given instructions, asked to experiment with this section-level design prototype, and evaluate the easiness and enjoyableness of the task. Testers ranged in age from 18 to 55, were from 5 different countries, and most had not previously edited Wikipedia. Three of the testers were male, and three were female. They were asked to review two image suggestions, one was a "good" image suggestion and one was a "bad" image suggestion.
Some key take-aways from the user testing:
- The onboarding was understood by all participants: “Clear, easy to understand, straightforward.”
- Participants seemed to understand the task and that they needed to focus on the section when making their decision. One participant accepted a "bad" image suggestion:
- 2/6 participants accepted the "good" image suggestion (3 rejected the image, 1 participant skipped it).
- 5/6 participants rejected the "bad" image suggestion.
- Note: the algorithm that powers image suggestions should provide more "good" suggestions than "bad" suggestions, but the algorithm isn't perfect, which is why this task needs human review and is suitable for new editors.
- Some participants mentioned wanting more than one image to review per section: “One suggestion is not enough, maybe you can present more images to choose from so I can select the most appropriate image.”
Algorithm evaluation
editThe Growth team aims to ensure structured tasks for newcomers provide suggestions to newcomers that are accurate at least 70% of the time. We have conducted several rounds of evaluation to review the accuracy of the image suggestion algorithm.
In the initial evaluation, suggestions were still fairly inaccurate (T316151). Many images were suggested in sections that shouldn't have images, or the image related to one topic in the section but didn't represent the section as a whole. Based on feedback from this evaluation, the Structured Data team continued to work on logic and filtering improvements to ensure suggestions were more accurate (T311814).
In the second evaluation, on average, suggestions were much better (T330784). Of course results varied widely by language, but the average accuracy was fairly high for many wikis. However, there are some wikis in which the suggestions are still not good enough to present to newcomers, unless we only utilized the "good intersection" suggestions. That would severely limit the number of image suggestions available, so we are looking instead at increasing the confidence score of the suggestions we provide.
| wiki | % good alignment | % good intersection | % good p18/p373/lead image | total rated suggestions |
|---|---|---|---|---|
| arwiki | 71 | 91 | 54 | 511 |
| bnwiki | 28 | 86 | 26 | 204 |
| cswiki | 41 | 77 | 23 | 128 |
| enwiki | 76 | 96 | 75 | 75 |
| eswiki | 60 | 67 | 48 | 549 |
| frwiki | N.A. | N.A. | 100 | 3 |
| idwiki | 66 | 81 | 37 | 315 |
| ptwiki | 92 | 100 | 84 | 85 |
| ruwiki | 73 | 89 | 69 | 250 |
| overall | 64 | 86 | 57 | 2,120 |
It's good to note that this task will be Community configurable via Special:EditGrowthConfig. We hope to improve the task to the point that it can work well on all wikis, but communities will ultimately decide if this task is a good fit and should remain enabled.
Community consultation
editA discussion with Growth pilot wikis is planned for May 2023 (T332530). We will post designs, plans, and questions at Arabic Wikipedia, Bengali Wikipedia, Czech Wikipedia, Spanish Wikipedia, as well as share further details here on MediaWiki.
Measurement
editWe decided to not deploy this feature in an A/B test and instead allow users to opt in to using it through the task selection dialogue on the Newcomer Homepage, or through the "Try a new task" post-edit dialogue that's part of the Levelling Up features. This meant that we focused on measuring a set of leading indicators to understand if the task was performing well. More details about this can be found in T332344.
We pulled data from Growth's KPI Grafana board from 2023-07-31 to 2023-08-28 (available here) for Section-Level and Article-Level suggestions. This timeframe was chosen because it should not be as much affected by the June/July slump in activity that we often see on the wikis. The end date is limited by the team shutting off image suggestions in late August (see T345188 for more information). This data range covers four whole weeks of data. While this dataset does not allow us to separate it by platform (desktop and mobile web), nor does it allow us more fine-grained user filtering, it was easily available and provides us with a reasonably good picture that's sufficient for this kind of analysis at this time. Using this dataset we get the overview of task activity shown in Table 1.
| Task type | Task clicks | Saved edits | Reverts | Task completion rate | Revert rate |
|---|---|---|---|---|---|
| Section-level | 1,149 | 688 | 60 | 58.1% | 9.0% |
| Article-level | 6,800 | 2,414 | 105 | 35.5% | 4.3% |
We see from the table that the task completion rate for section-level image suggestions is high, on par with Add a Link (ref) when that was released. This is likely because the section-level task is something users either choose themselves in the task selection dialogue, or choose to try out after being asked through the "Try a new task" dialogue that's part of Levelling Up. Those users are therefore likely already experienced editors and don't have too many issues with completing this task.
The revert rate for the section-level task is higher than the article-level task. We don't think this difference is cause for concern for two reasons. First, it might be harder to agree that an article is clearly improved by adding a section-level image compared to adding an article-level image. Secondly, articles suggested for section-level images already have a lead image, which might mean that they're also longer and have more contributors scrutinizing the edit.