النمو/اليوم الأول المعدّل/المهام المهيكلة/إضافة صورة
هذه الصفحة تصف العمل على المهمّة المهيكلة «إضافة صورة»، التي هي نوع من المهام المهيكلة التي سيُوفرها فريق النمو عبر لوحة المستخدم الخاصة بالوافدين الجدد.
|
Add an image
Suggest images from Commons that newcomers could add to Wikipedia articles
|

تحتوي الصفحة على أهداف رئيسة وتصاميم وأسئلة مفتوحة وقرارات.
ملخّص هذا المشروع:
|
سيتم نشر معظم الأخبار الخاصة بتدرّج العمل في الصفحة العامة لـأخبار فريق النمو، مع نشر بعض الأخبار الهامّة أو المفصّلة هنا.
الوضع الحالي
- 2020-06-22: التفكير الأوّلي حول إنجاز خوارزمية بسيطة للصور الموصى باستخدامها
- 2020-09-08: تقييم المحاولة الأولى باللغات الإنكليزية والفرنسية والعربية والكورية والتشيكية والفيتنامية
- 2020-09-30: تقييم المحاولة الثانية عند خوارزمية تَطابُق بالإنكليزية والفرنسية والعربية والكورية والتشيكية والفيتنامية
- 2020-10-26: نقاش داخلي بين المهندسين حول جدوى خدمة الصور الموصى بها
- 2020-12-15: إجراء جولة أولى من اختبارات المستخدمين للبدء بفهم ما إذا كان الوافدون الجدد سينجحون في هذه المهمة
- 2021-01-20: يبدأ فريق هندسة النظام الأساسي في إنشاء واجهة برمجة تطبيقات لإثبات المفهوم لتوصيات الصور
- 2021-01-21: يبدأ فريق الأندرويد العمل على الحد الأدنى من الإصدار القابل للتطبيق لأغراض التعلم
- 2021-01-28: جرى نشر نتائج اختبار المستخدم
- 2021-02-04: جرى نشر ملخّص نقاشات المجتمعات وإحصائيات التغطية
- 2021-05-07: جرى إصدار أندرويد MVP للمستخدمين
- 2021-08-06: النتائج المنشورة من الأندرويد والنماذج التقريبية للتكرار 1
- 2021-08-17: بدأ العمل الخلفي (backend work) على التكرار 1
- 2021-08-23: نشر نماذج تقريبية تفاعلية وبدأ اختبارات المستخدم باللغتين الإنجليزية والإسبانية
- 2021-10-07: نشر نتائج من اختبارات المستخدم والتصاميم النهائية بناءً على النتائج
- 2021-11-19: اختبار السفراء لهذه المِيزة في ويكيبيديا العمل الخاصة بهم
- 2021-11-22: تحديث مجموعة بيانات اقتراح الصور قبل إصدار التكرار 1 للمستخدمين
- 2021-11-29: نشر التكرار 1 لـ 40% من مستخدمي الأجهزة الجوالة في الويكيبيديات العربية والتشيكية والبنغالية.
- 2021-12-22: تم نشر المؤشّرات القيادية
- 2022-01-28: نشر النسخة المكتبية لـ 40% من الحسابات الجديدة في الويكيبيديات العربية والتشيكية والبنغالية.
- 2022-02-16: بدء الوافدون الجدد في الويكيبيديا الإسبانية بالحصول على «إضافة صورة»
- 2022-03-22: الوافدون الجدد في الويكيبيديات باللغات الفارسية والفرنسية والتركية بدؤوا في الحصول على «إضافة صورة»
- 2023-02-07: Complete evaluation of section-level image suggestions (T316151)
- 2023-10-16: Image Recommendations added to the Android Wikipedia app
- 2024-04-11: Publish "Add an image" Experiment Analysis
- التالي: Release "Add an image" to more Wikipedias
ملخص
الهدف من المهام المهيكلة هو تقسيم مهام التحرير إلى مسارات عمل خطوة بخطوة من شأنها أن تناسب الوافدين الجدد وأن تناسب الأجهزة المحمولة. يعتقد فريق النمو أنّ تقديم هذه الشاكلة من مسارات العمل سيسمح لعدد أكبر من الأشخاص بالبَدْء بالمساهمة في ويكيبيديا، بعضهم سيتعلّم القيام بتعديلات جوهريّة والانخراط مع مجتمعاتهم. بعد النقاش حول المهام المهيكلة مع المجتمعات، قرّرنا إنشاء المهمّة المهيكلة الأولى: «إضافة رابط». The Growth team believes that introducing these new kinds of editing workflows will allow more new people to begin participating on Wikipedia, some of whom will learn to do more substantial edits and get involved with their communities. After discussing the idea of structured tasks with communities, we decided to build the first structured task: "add a link".
بعد نشر «إضافة رابط» في شهر مايو 2021، جمعنا بيانات أولية تظهر أنّ المهمّة كانت مشرّكة للوافدين الجدد، وأنهم قاموا بتعديلات ذات نسبة استرجاع متدنّية -- تظهر أنّ المهام المهيكلة هي ذات قيمة لتجربة الوافدين الجدد ولمواقع الويكي.
خلال إنشائنا لتلك المهمة الأولى، كان تفكيرنا في ما هي المهمة الموالية التي يمكن أن تكون، ونحن نعتقد أن إضافة الصور يمكن أن تكون مناسبة جدا للوافدين الجدد. تكمن الفكرة في خوارزمية بسيطة تستطيع اقتراح وضع صور ورسومات من كومنز في مقالات لا تحمل أي صور. بادئا، ستقوم فقط باستخدام الروابط الموجودة التي يمكن العثور عليها في ويكيبيانات، وسيتمكّن الوافدون الجدد من استخدام تقديرهم الخاص لوضع الصورة في المقالة من عدمه.
نعلم أنّه هنالك العديد من الأسئلة المفتوحة حول كيفية القيام بهذا، ووجود العديد من الأسباب الكامنة حول إمكانية سلوك طريق خاطئة. لذلك سنستمع إلى آراء أفراد المجتمع وسنجري محادثات مواكبة لكيفية تعاملنا مع طريقة العمل.
المشاريع ذات الصلة
اشتغل فريق الأندرويد على نسخة مصغّرة لمهمّة مماثلة في تطبيق ويكيبيديا على الأندرويد باستخدام نفس المكوّنات الأساسية.
بالإضافة إلى أنّ فريق البيانات الهيكليّة هو في المراحل الأولى من تجرِبة شيء مماثل، موجّه إلى مستخدمين أكثر خبرة مع استغلال البيانات المهيكلة في كومنز.
الصور، لماذا؟
| وسّع لقراءة قسم «الصور، لماذا؟» |
|---|
|
البحث عن المساهمات الثرية عندما ناقشنا أوّل مرة المهام المنظمة مع أعضاء المجتمع، أشار الكثيرون، بشكل خاص، إلى أن إضافة روابط ويكي ليست مهمة تحريرية عالية القيمة. طرح أعضاء المجتمع أفكارًا حول كيفية قيام الوافدين الجدد بتقديم المزيد من المساهمات الجوهرية. أحد الأفكار كان إضافة الصور. تحتوي ويكيميديا كومنز على 65 مليون صورة، ولكن في العديد من مواقع الويكي، أكثر من 50% من المقالات لا تحتوي على صور. نعتقد أن العديد من الصور من كومنز يمكن أن تجعل ويكيبيديا أكثر وضوحًا بشكل كبير. Community members brought up ideas for how newcomers could make more substantial contributions. One idea is images. يحتوي ويكيميديا كومنز على 65 مليون صورة. نعتقد أن العديد من الصور على كومنز من يمكن أن تجعل ويكيبيديا أكثر وضوحًا بشكل كبير. الاهتمام من الوافدين الجدد نعلم أن العديد من الوافدين الجدد مهتمون بإضافة الصور إلى ويكيبيديا. «إضافة صورة» هو رد شائع يقدمه القادمون الجدد في استطلاع الترحيب عن سبب إنشائهم لحسابهم. نرى أيضًا أن أكثر أسئلة لوحة المساعدة شيوعًا يتعلق بكيفية إضافة الصور، وهذا صحيح عبر جميع مواقع الويكي التي نعمل معها. مع أنّ معظم هؤلاء الوافدين الجدد ربما يجلبون الصور الخاصة التي يريدون إضافتها، فإن هذا يلمّح إلى كيف يمكن أن تكون الصور مدعاة للمشاركة ومثيرة. وهذا أمر منطقي، بالنظر إلى الوزن الكبير للصور في المنصات الأخرى التي يستخدمها الوافدون الجدد -- كانستغرام وفيسبوك. صعوبة التعامل مع الصور تعكس أسئلة طلبات المساعدة العديدة حول الصور أن عملية إضافتها إلى المقالات صعبة للغاية. يجب على الوافدين الجدد فهم الفرق بين ويكيبيديا وكومنز، والقواعد المتعلقة بحقوق النشر، والأجزاء الفنية لإدراج الصورة والتعليقات في المكان المناسب. يتطلب العثور على صورة في كومنز لمقال ما، مزيدًا من المهارات، مثل المعرفة بويكيبيانات والتصنيفات. نجاح حملة «صفحات ويكيبيديا بحاجة لصور» كان لـحملة صفحات ويكيبيديا بحاجة لصور (WPWP) نجاح غير متوقع: أضاف 600 مستخدم صورة إلى 85,000 صفحة. قاموا بذلك بمساعدة بعض أدوات المجتمع التي قامت بتشخيص الصفحات التي ليس لها صور، والتي اقترحوا لها صورا محتملة عبر ويكيبيانات. في حين أن هناك دروسًا مهمة يجب تعلمها حول كيفية مساعدة الوافدين الجدد على النجاح في إضافة الصور، فإن هذا يمنحنا الثقة في أن المستخدمين يمكن أن يكونوا متحمسين لإضافة الصور وأنه يمكن مساعدتهم بالأدوات. باعتبار كلّ ما سبق ذكره بالتفكير في كل هذه المعلومات معا، نعتقد أنّه من الممكن بناء المهمّة المهيكلة «إضافة صورة» التي ستكون مُرََوِّحة للوافدين الجدد وفي الآن نفسه بنّاءة لمواقع الويكيبيديا. |
التحقق من صحة الفكرة
منذ يناير 2020 حتى يوليو 2021، عمل فريق النموّ على نقاشات المجتمع والبحوث الخلفية، والتقييمات، وعلى إثبات المفاهيم حول مهمّة «إضافة صورة». أدى ذلك إلى قرار البَدْء في إنشاء أول تكرار (iteration) لنا في أغسطس 2021 (طالع تكرار 1). يحتوي هذا القسم على كل الأعمال الخلفية المؤدية إلى التكرار 1.
| وسّع لقراءة قسم «التحقق من صحة الفكرة» | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
الخوارزميةتعتمد قابليتنا لإنشاء مهمّة مهيكلة تُعنى بإضافة الصور إلى ما إذا استطعنا إنشاء خوارزمية تولّد توصيات جيّدة بما فيه الكفاية. قطعا، لا نريد مطالبة الوافدين الجدد بإضافات سريعة لصور خاطئة للمقالات، التي يمكن أن تجبر المحرّرين أن يقوموا بالتنظيف وراءهم. وبالتالي، فإن محاولة إنشاء خوارزمية جيّدة، كان من أوّل الأمور التي عملنا عليها.
المنطقاشتغلنا مع فريق البحث لويكيميديا، وإلى حدّ الآن، تمكنا من تجربة خوارزمية أعطت الأولوية إلى الدقة والحكم البشري. بالنأي عن استخدام أيّة رؤية حاسوبية، التي يمكن أن تولّد نتائج غير منتظرة، ببساطة هي تجمّع معلومات من ويكيبيانات، بالاعتماد على الاتصالات التي أجراها المساهمون المتمرسون. فيما يلي الطرق الرئيسية الثلاث التي تُقترح بها المطابقات مع المقالات التي لا تحتوي صورا:
تتضمن الخوارزمية أيضًا منطقًا للقيام بأشياء مثل استبعاد الصور التي من المحتمل أن تكون أيقونات أو الموجودة في مقالة كجزء من صندوق التصفح.
الدقةاعتبارًا من أغسطس 2021، مررنا بـ 3 جولات من اختبار الخوارزمية، في كل مرة نبحث عن مطابقة المقالات في ست لغات: الإنجليزية والفرنسية والعربية والفيتنامية والتشيكية والكورية. تم إجراء التقييمات من قبل سفراء فريقنا، ومن قبل ويكيميديين خبيرين آخرين، وهم متحدّثون أصليون لهذه اللغات التي تم اختبارها. التقييمان الأولان لاحظنا في 50 تطابقا مقترحا في كل لغة، مررنا عليها كلها وصنّفناها ضمن هذه المجموعات:
السؤال الذي يدور حول العمل على خوارزمية مثل هذه هو: ما مدى الدقة التي يجب أن تكون؟ إذا كانت 75% من التطابقات جيدة، فهل هذا كافٍ؟ هل يجب أن تكون دقيقة بنسبة 90%؟ أو يمكن أن تكون دقيقة بنسبة 50%؟ هذا يعتمد على مدى جودة الحكم على الوافدين الجدد الذين يستخدمونها، ومقدار الصبر الذي لديهم للتطابقات الضعيفة. سنتعلم المزيد عن هذا عندما نختبر الخوارزمية مع مستخدمين جدد حقيقيين. في التقييم الأول، كان الشيء الأكثر أهمية هو أننا وجدنا الكثير من التحسينات السهلة لإدخالها على الخوارزمية، بما في ذلك أنواع المقالات والصور التي يجب استبعادها. حتى دون هذه التحسينات، كان حوالي 20-40% من التطابقات «2s»، مما يعني تطابقًا جيدا مع المقالة (حسب الويكي). يمكنكم مشاهدة النتائج الكاملة والملاحظات من التقييم الأول هنا. في التقييم الثاني، تم إدخال العديد من التحسينات، وزادت الدقة. بين 50-70% من التطابقات كانت "2s" (حسب الويكي). لكن زيادة الدقة يمكن أن تقلل من التغطية، أي عدد المقالات التي يمكننا إجراء مطابقات لها. باستخدام معايير متحفظة، قد تكون الخوارزمية قادرة فقط على اقتراح عشرات الآلاف من التطابقات في ويكي معين، حتى لو كان هذا الويكي يحتوي على مئات الآلاف أو ملايين المقالات. نعتقد أن هذا الحجم سيكون كافيًا لإنشاء نسخة أولية من هذه المِيزة. يمكنكم مشاهدة النتائج الكاملة والملاحظات من التقييم الثاني هنا. التقييم الثالث في مايو 2021، أجرى فريق البيانات المهيكلة اختبارا على نطاق واسع لخوارزمية مطابقة الصورة (وخوارزمية MediaSearch) في الويكيبيديا باللغات العربية، والسيبوانية، والإنجليزية، والفيتنامية، والبنغالية، والتشيكية. وفي هذا الاختبار، جرى تقييم حوالي 500 مُطابقة من كل من خوارزمية مطابقة الصورة وMediaSearch من قبل الخبراء في كل لغة، الذين استخدموا وصفًا مثل: «جيد» أو «أوكي» أو «سيئ» لتقييم المُطابقة. النتائج المفصلة أدناه توضح ذلك:
كامل مجموعة نتائج البيانات موجودة هنا. التغطيةإن دقة الخوارزمية هي عنصر مهم للغاية. وبنفس القدر من الأهمية يكون «مدى تغطيتها» -- هذا يشير إلى كم مرة تطابقٍ للصورة يُمكنها القيام به. قد تكون الدقة والتغطية على ارتباط عكسي: فكلما زادت دِقة الخوارزمية، فإن اقتراحاتها تقل (نظرا لأنها ستقترح فقط عندما تكون واثقة). نحتاج إلى الإجابة على هذه الأسئلة: هل الخوارزمية قادرة على توفير ما يكفي من المطابقات بدرجة تجعل من المُفيد بناء مِيزة خاصة بها؟ هل ستكون قادرة على تحقيق تأثير كبير على الويكي؟ تطرّقنا إلى 22 موقع ويكيبيديا للحصول على الإجابات. الجدول أدناه، يلخّص هذه النِّقَاط:
البحث في الوسائط MediaSearchكما ذكرنا سابقًا، يستكشف فريق البيانات المهيكلة استخدام خوارزمية MediaSearch لزيادة التغطية وتحقيق المزيد من المطابقات المرشحة. يعمل MediaSearch من خلال الجمع بين البحث التقليدي المستند إلى النص والبيانات المنظمة لتقديم نتائج ذات صلة لعمليات البحث بطريقة لا تعرف اللغة. باستخدام عبارات ويكي-بيانات المضافة إلى الصور كجزء من البيانات المهيكلة على كومنز كمدخل لترتيب البحث، تستطيع MediaSearch الاستفادة من الأسماء المستعارة والمفاهيم ذات الصلة والتسميات بلغات متعددة لزيادة صلة مطابقة الصورة. يمكنك العثور على مزيد من المعلومات حول كيفية عمل MediaSearch هنا. اعتبارًا من فبراير 2021، قام الفريق بتجربة كيفية توفير درجة ثقة لمطابقات MediaSearch التي يمكن أن تستهلكها خوارزمية توصيات الصور وتستخدمها لتحديد ما إذا كانت المطابقة من MediaSearch ذات جودة كافية لاستخدامها في مهام مطابقة الصور. نريد أن نتيقن من ثقة المستخدمين في التوصيات التي يقدمها MediaSearch قبل دمجها في المِيزة. يقوم فريق البيانات المهيكلة أيضًا باستكشاف وإنشاء نماذج أولية لطريقة تستخدم فيها برامج البوت -الخاصة بالمستخدمين- النتائج الصادرة عن كل من خوارزمية اقتراح الصور و MediaSearch لإضافة الصور تلقائيًا إلى المقالات. ستكون هذه تجربة في مواقع الويكي ذات البوتات الثقيلة، بالشراكة مع مؤلفي البوتات المجتمعية. يمكنك معرفة المزيد حول هذا الجهد أو التعبير عن الاهتمام بالمشاركة في مهمة phabricator. في مايو 2021، في نفس التقييم المذكور في قسم «الدقة» أعلاه، وجد أن MediaSearch أقل دقة بكثير من خوارزمية مطابقة الصور. حيث كانت خوارزمية مطابقة الصور دقيقة بنسبة 78%، وكانت المطابقات من MediaSearch دقيقة بنسبة 38%. لذلك، لا يخطط فريق النموّ لاستخدام MediaSearch في التكرار الأول لمهمة «إضافة صورة». أسئلة ونقاشات
أسئلة مفتوحةالصور جزء مهم ومرئي من تجرِبة ويكيبيديا. من الأهمية بمكان أن نفكر مليًا في كيفية عمل مِيزة تتيح الإضافة السهلة للصور، وما هي المخاطر المحتملة، وما هي الآثار المترتبة على أعضاء المجتمع. لتحقيق هذه الغاية، لدينا العديد من الأسئلة المفتوحة، ونريد أن نسمع المزيد من الأسئلة التي يمكن لأعضاء المجتمع طرحها.
ملاحظات من مناقشات المجتمع 2021-02-04بدءًا من ديسمبر 2020، قمنا بدعوة أعضاء المجتمع للتحدث عن فكرة «إضافة صورة» بخمس لغات (الإنجليزية، البنغالية، العربية، الفيتنامية، التشيكية). جرت مناقشة اللغة الإنجليزية في الغالب على صفحة المناقشة هنا، مع محادثات باللغة المحلية في الويكيبيديات الأربع الأخرى. تلقينا آراءً 28 فردا من أعضاء المجتمع، وهذا القسم يلخص بعض الأفكار الأكثر شيوعًا وإثارة للاهتمام. تؤثر هذه المناقشات بشدة على مجموعتنا التالية من التصميمات.
مخطّط لاختبار المستخدم بالتفكير في الأسئلة المفتوحة أعلاه، بالإضافة إلى مدخلات المجتمع، نريد إنشاء بعض المعلومات الكَمّيَّة والنوعية لمساعدتنا في تقييم جدوى بناء مِيزة «إضافة صورة». مع أنّنا قمنا بتقييم الخوارزمية بين الموظفين ومستخدمي ويكيميديا، فمن المهم أن نرى كيف يتفاعل الوافدون الجدد معها، ونرى كيف يستخدمون حُكمهم عند اتخاذ قرار بشأن ما إذا كانت الصورة تنتمي إلى مقالة. لحقيق لهذه الغاية، سنجري اختبارات مع usertesting.com، حيث يمكن للأشخاص الجدد في تحرير ويكيبيديا المرور عبر تطابقات الصور المحتملة في نموذج أولي والرد بـ «نعم» أو «لا» أو «غير متأكد». قمنا ببناء نموذج أولي سريع للاختبار، مدعومًا بتطابقات حقيقية من الخوارزمية الحالية. يعرض النموذج الأولي تطابقا واحدا فقط تلو الآخر، كل ذلك في مسار واحد. يتم عرض الصور مع جميع البيانات الوصفية ذات الصلة من كومنز:
على الرغم من أن هذا قد لا يكون نفس ما سيكون عليه سير العمل بالنسبة للمستخدمين الحقيقيين في المستقبل، فقد تم إنشاء النموذج الأولي بحيث يمكن للمختبرين إجراء الكثير من التطابقات المحتملة بسرعة، مما ينتج عنه الكثير من المعلومات. لتجربة النموذج الأولي التفاعلي، استخدموا هذا الرابط. لاحظوا أن هذا النموذج الأولي مخصص بشكل أساسي لعرض التطابقات من الخوارزمية -- لم نفكر بعد مليًا في تجرِبة المستخدم الفعلية. لا يقوم في الواقع بإنشاء أي تعديلات. يحتوي على 60 تطابقًا حقيقيًا اقترحته الخوارزمية. إليكم ما سنبحث عنه في الاختبار:
التصميممفهوم A ضدّ Bعند التفكير في تصميم هذه المهمة، لدينا سؤال مشابه كما واجهناه بخصوص «إضافة رابط» فيما يتعلق بالمفهوم A والمفهوم B. في المفهوم A، سيكمل المستخدمون التحرير في المقالة، بينما في المفهوم B، فإنهم يقومون بالعديد من التعديلات على التوالي كل ذلك عبر سيل. يمنح المفهوم A المستخدم مزيدًا من السياق للمقالة والتحرير، بينما يعطي المفهوم B الأولوية للكفاءة. في النموذج الأولي التفاعلي أعلاه، استخدمنا المفهوم B، حيث ينتقل المستخدمون من خلال سيل من الاقتراحات. لقد قمنا بذلك لأنه في اختبارات المستخدم الخاصة بنا أردنا رؤية العديد من الأمثلة للمستخدمين الذين يتفاعلون مع الاقتراحات. هذا هو نوع التصميم الذي قد يعمل بشكل أفضل لمنصة مثل تطبيق ويكيبيديا على الأندرويد. بالنسبة لسياق فريق النموّ، فإننا نفكر أكثر على غرار المفهوم A، حيث يقوم المستخدم بالتعديل «في المقالة». هذا هو الاتجاه الذي اخترناه لـ «إضافة رابط»، ونعتقد أنه قد يكون مناسبًا لـ «إضافة صورة» للأسباب نفسها. وحيدة ضدّ متعدّدةهناك سؤال مهم آخر يتعلق بالتصميم وهو ما إذا كان يجب إظهار تطابق صورة مقترحة وحيدة للمستخدم، أو منحهم عدة صور مطابقة للاختيار من بينها. عند تقديم العديد من التطابقات، هناك احتمال أكبر أن تكون إحدى المباريات جيدة. ولكنه قد يجعل المستخدمين يعتقدون أيضًا أنه يجب عليهم اختيار واحد منهم، حتى لو لم يكن أي منهم جيدًا. ستكون أيضًا تجربة أكثر تعقيدًا في التصميم والبناء، خاصة للأجهزة المحمولة. لقد تصوّرنا ثلاثة سيول عمل محتملة:
   اختبارات المستخدم كانون الأول (ديسمبر) 2020خلفية خلال شهر كانون الأول (ديسمبر) 2020، استخدمنا usertesting.com لإجراء 15 اختبارًا النموذج الأولي التفاعلي للجوال. احتوى النموذج الأولي فقط على تصميم بدائي، أو سياق صغير أو إعداد عمل، وتم اختباره باللغة الإنقليزية فقط مع مستخدمين لديهم خبرة قليلة في تحرير ويكيبيديا أو ليس لديهم خبرة سابقة في تحرير ويكيبيديا. اختبرنا تصميمًا بدائيًا عن عمد في وقت سابق من العملية حتى نتمكن من جمع الكثير من المعلومات. كانت الأسئلة الأساسية التي أردنا معالجتها في هذا الاختبار حول جدوى المِيزة ككلّ، وليس حول نِقَاط التصميم الدقيقة:
In the test, we asked participants to annotate at least 20 article-image matches while talking out loud. When they tapped yes, the prototype asked them to write a caption to go along with the image in the article. Overall, we gathered 399 annotations. Summary We think that these user tests confirm that we could successfully build an "add an image" feature, but it will only work if we design it right. Many of the testers understood the task well, took it seriously, and made good decisions -- this gives us confidence that this is an idea worth pursuing. On the other hand, many other users were confused about the point of the task, did not evaluate as critically, and made weak decisions -- but for those confused users, it was easy for us to see ways to improve the design to give them the appropriate context and convey the seriousness of the task. Observations To see the full set of findings, feel free to browse the slides. The most important points are written below the slides. 
القياسات
Takeaways
البيانات الوصفيةThe user tests showed us that image metadata from Commons (e.g. filename, description, caption, etc.) is critical for a user to confidently make a match. For instance, though the user can see that the article is about a church, and that the photo is of a church, the metadata allowed them to tell if it is the church discussed in the article. In the user tests, we saw that these items of metadata were most important: filename, description, caption, categories. Items that were not useful included size, upload date, and uploading username. Given that metadata is a critical part of making a strong decision, we have been thinking about whether users will need to be have metadata in their own language in order to do this task, especially in light of the fact that the majority of Commons metadata is in English. For 22 wikis, we looked at the percentage of the image matches from the algorithm that have metadata elements in the local language. In other words, for the images that can be matched to unillustrated articles in Arabic Wikipedia, how many of them have Arabic descriptions, captions, and depicts? The table is below these summary points:
Given that local-language metadata has low coverage, our current idea is to offer the image matching task to just those users who can read English, which we could ask the user as a quick question before beginning the task. This unfortunately limits how many users could participate. It's a similar situation to the Content Translation tool, in that users need to know the language of the source wiki and the destination wiki in order to move content from one wiki to another. We also believe there will be sufficient numbers of these users based on results from the Growth team's welcome survey, which asks newcomers which languages they know. Depending on the wiki, between 20% and 50% of newcomers select English. Android MVPSee this page for the details on the Android MVP. BackgroundAfter lots of community discussion, many internal discussions, and the user test results from above, we believe that this "add an image" idea has enough potential to continue to pursue. Community members have been generally positive, but also cautionary -- we also know that there are still many concerns and reasons the idea might not work as expected. The next step we want to in order to learn more is to build a "minimum viable product" (MVP) for the Wikipedia Android app. The most important thing about this MVP is that it will not save any edits to Wikipedia. Rather, it will only be used to gather data, improve our algorithm, and improve our design. The Android app is where "suggested edits" originated, and that team has a framework to build new task types easily. These are the main pieces:
ResultsThe Android team released the app in May 2021, and over several weeks, thousands of users evaluated tens of thousands of image matches from the image matching algorithm. The resulting data allowed the Growth team to decide to proceed with Iteration 1 of the "add an image" task. In looking at the data, we were trying to answer two important questions around "Engagement" and "Efficacy". Engagement: do users of all languages like this task and want to do it?
Efficacy: will resulting edits be of sufficient quality?
See the full results are here. هندسياتThis section contains links on how to follow along with technical aspects of this project: |
Iteration 1
In July 2021, the Growth team decided to move forward with building a first iteration of an "add an image" task for the web. This was a difficult decision, because of the many open questions and risks around encouraging newcomers to add images to Wikipedia articles. But after going through a year of idea validation, and looking through the resulting community discussions, evaluations, tests, and proofs-of-concepts around this idea, we decided to build a first iteration so that we could continue learning. These are the main findings from the idea validation phase that led us to move forward:
- Cautious community support: community members are cautiously optimistic about this task, agreeing that it would be valuable, but pointing out many risks and pitfalls that we think we can address with good design.
- Accurate algorithm: the image matching algorithm has shown to be 65-80% accurate through multiple different tests, and we have been able to refine it over time.
- User tests: many newcomers who experienced prototypes found the task fun and engaging.
- Android MVP: the results from the Android MVP showed that newcomers generally applied good judgment to the suggestions, but more importantly, gave us clues about how to improve their results in our designs. The results also hinted that the task could work well across languages.
- Overall learnings: having bumped into many pitfalls through our various validation steps, we'll be able to guard against them in our upcoming designs. This background work has given us lots of ideas on how to lead newcomers to good judgment, and how to avoid damaging edits.
Hypotheses
We're not certain that this task will work well -- that's why we plan to build it in small iterations, learning along the way. We do think that we can make a good attempt using our learnings so far to build a lightweight first iteration. One way to think about what we're doing with our iterations is hypothesis testing. Below are five optimistic hypotheses we have about the "add an image" task. Our aim in Iteration 1 will be to see if these hypotheses are correct.
- Captions: users can write satisfactory captions. This is our biggest open question, since images that get placed into Wikipedia articles generally require captions, but the Android MVP did not test the ability of newcomers to write them well.
- Efficacy: newcomers will have strong enough judgment that their edits will be accepted by the communities.
- Engagement: users like to do this task on mobile, do many, and return to do more.
- Languages: users who don’t know English will be able to do this task. This is an important question, since the majority of metadata on Commons is in English, and it is critical for users to read the filename, description, and caption from Commons in order to confidently confirm a match.
- Paradigm: the design paradigm we built for "the add a link structured task" will extend to images.
Scope
Because our main objective with Iteration 1 is learning, we want to get an experience in front of users as soon as we can. This means we want to limit the scope of what we build so that we can release it quickly. Below are the most important scope limitations we think we should impose on Iteration 1.
- Mobile only: while many experienced Wikimedians do most of the wiki work from their desktop/laptop, the newcomers who are struggling to contribute to Wikipedia are largely using mobile devices, and they are the more important audience for the Growth team's work. If we build Iteration 1 only for mobile, we'll concentrate on that audience while saving the time it would take to additionally design and build the same workflow for desktop/laptop.
- Static suggestions: rather than building a backend service to continuously run and update the available image matches using the image matching algorithm, we'll run the algorithm once and use the static set of suggestions for Iteration 1. While this won't make the newest images and freshest data available, we think it will be sufficient for our learning.
- Add a link paradigm: our design will generally follow the same patterns as the design for our previous structured task, "add a link".
- Unillustrated articles: we'll limit our suggestions only to articles that have no illustrations in them at all, as opposed to including articles that have some already, but could use more. This will mean that our workflow will not need to include steps for the newcomer to choose where in the article to place the image. Since it will be the only image, it can be assumed to be the lead image at the top of the article.
- No infoboxes: we'll limit our suggestions only to articles that have no infoboxes. That's because if an unillustrated article has an infobox, its first image should usually be placed in the infobox. But it is a major technical challenge to make sure we can identify the correct image and image caption fields in all infoboxes in many languages. This also avoids articles that have Wikidata infoboxes.
- Single image: although the image matching algorithm can propose multiple image candidates for a single unillustrated article, we'll limit Iteration 1 to only proposing the highest-confidence candidate. This will make for a simpler experience for the newcomer, and for a simpler design and engineering effort for the team.
- Quality gates: we think we should include some sort of automatic mechanism to stop a user from making a large number of bad edits in a short time. Ideas around this include (a) limiting users to a certain number of "add an image" edits per day, (b) giving users additional instructions if they spend too little time on each suggestions, (c) giving users additional instructions if they seem are accepting too many images. This idea was inspired by English Wikipedia's 2021 experience with the Wikipedia Pages Wanting Photos campaign.
- Pilot wikis: as with all new Growth developments, we will deploy first only to our four pilot wikis, which are Arabic, Vietnamese, Bengali, and Czech Wikipedias. These are communities who follow along with the Growth work closely and are aware that they are part of experiments. The Growth team employs community ambassadors to help us correspond quickly with those communities. We may add Spanish and Portuguese Wikipedias to the list in the coming year.
We're interested to hear community members' opinions on if these scoping choices sound good, or if any sound like they would greatly limit our learnings in Iteration 1.
التصميم
Mockups and prototypes
Building on designs from our previous user tests and on the Android MVP, we are considering multiple design concepts for Iteration 1. For each of five parts of the user flow, we have two alternatives. We'll user test both to gain information from newcomers. Our user tests will take place in English and Spanish -- our team's first time testing in a non-English language. We also hope community members can consider the designs and provide their thoughts on the talk page.
Prototypes for user testing
The easiest way to experience what we're considering to build is through the interactive prototypes. We've built prototypes for both the "Concept A" and "Concept B" designs, and they are available in both English and Spanish. These are not actual wiki software, but rather a simulation of it. That means that no edits are actually saved, and not all the buttons and interactions work -- but the most important ones relevant to the "add an image" project do work.
نماذج بالأحجام الطبيعية لاختبار المستخدم
Below are static images of the mockups that we're using for user testing in August 2021. Community members are welcome to explore the Growth team designer's Figma file, which contains the mockups below in the lower right of the canvas, as well as the various pieces of inspiration and notes that led to them.
Feed
These designs refer to the very first part of the workflow, in which the user chooses an article to work on from the suggested edits feed. We want the card to be attractive, but also not confuse the user.
-
 Concept A: contains obscured thumbnail of suggested image, giving the user some visuals about the upcoming task.
Concept A: contains obscured thumbnail of suggested image, giving the user some visuals about the upcoming task. -
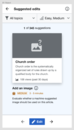 Concept B: no thumbnail of image, so that the user doesn't start to falsely feel like the proposed image "belongs" with the article.
Concept B: no thumbnail of image, so that the user doesn't start to falsely feel like the proposed image "belongs" with the article.


الأخذ باليد
These designs refer to what the user sees after opening up their first task, meant to explain what the task is and how to do a good job. We want the user to understand that adding an image is a consequential edit that needs to be considered seriously. Note that this exact text has not been designed carefully yet -- rather, we are thinking now about the experience through which we deliver this content.
-
 Concept A: full screen overlays explaining the concepts and steps of adding an image.
Concept A: full screen overlays explaining the concepts and steps of adding an image. -
 Concept B: sequential popups pointing to the elements for the different parts of the workflow.
Concept B: sequential popups pointing to the elements for the different parts of the workflow.


إضافة الصورة
These designs refer to the part of the workflow in which the user sees the suggested image, views its metadata from Commons, and decides whether to add it to the article. We know from user tests that it is important for the user to read the image title, Commons description, and Commons caption in order to make this decision correctly. This is a challenging part of the design: making all that information available on the mobile screen.
-
 Concept A: suggested image is shown in place where it will go in the article, giving the user the sense that adding the image will, in fact, put it on the article. User can expand the image to view it fullscreen and tap the "i" to see more metadata.
Concept A: suggested image is shown in place where it will go in the article, giving the user the sense that adding the image will, in fact, put it on the article. User can expand the image to view it fullscreen and tap the "i" to see more metadata. -
 Concept B: suggested image is shown in the "image inspector" card, along with the Commons metadata that goes with the image. User can expand the image to view it fullscreen.
Concept B: suggested image is shown in the "image inspector" card, along with the Commons metadata that goes with the image. User can expand the image to view it fullscreen.


وصف ونشر
These designs refer to the part of the workflow after the user has decided to add an image to the article, and is now writing a caption to go with it. This may be the most challenging part for the newcomer, and we are still thinking about how to help them understand what sort of caption is appropriate.
-
 Concept A: caption added via the existing Visual Editor caption dialog on its own screen.
Concept A: caption added via the existing Visual Editor caption dialog on its own screen. -
 Concept B: caption added in place on the article, helping the user understand the context for where the caption will be seen.
Concept B: caption added in place on the article, helping the user understand the context for where the caption will be seen.


Rejection
When a user rejects a suggestion, we want to collect data on why the match was wrong, so that we can improve the algorithm. This is also an opportunity to continually remind the user about the evaluation criteria they should be using as they evaluate images.
-
 Concept A: user can only choose one option.
Concept A: user can only choose one option. -
 Concept B: user can choose multiple options.
Concept B: user can choose multiple options.


User test results September 2021
In August 2021, we ran 32 user tests amongst people who were new to Wikipedia editing, using respondents from usertesting.com. Half the respondents walked through Concept A and half through Concept B. In order to represent more diverse perspectives, this was the first time that the Growth team ran user tests outside of English: 11 respondents took the test in Spanish, all of whom were located outside the United States. This will help us make sure we're building a feature that is valuable and understandable for populations around the world.
Our goals for the testing were to identify which parts of the design concepts worked best, and to surface any other potential improvements. These are our main findings and changes to the designs we plan to make.
- Findings
- Concept B clearly performed better for participants in both English and Spanish tests, particularly:
- Better understanding of the task. In Concept A, users sometimes thought the image was already in the article, because of its preview on the suggested edit card and the preview in the article.
- More careful engagement and consideration of article contents and image metadata when evaluating image suitability to an article. We suspect this is because the article and metadata areas were clearly separated.
- Greater use of image details and article contents during caption composition. The Concept B caption experience shows the full article text.
- Other notes
- Most people misunderstood the task initially as uploading images when they opened the Suggested edits module, regardless of design. But expectation about self-sourcing images was immediately corrected for almost all participants as soon as they opened the task, and overall, Design B evoked better task comprehension and successful image evaluation than Design A.
- Newcomers would benefit from more user education around Commons and use of images on Wikipedia articles in their understanding of the broader editing ecosystem of Wikipedia and its sister projects.
- Users understood the purpose of the caption, and understood that it would be displayed with the image in the Wikipedia article.
- Spanish participants were far more interwiki-attuned than English participants. Potentially explore ways to better cater to multilingual/cross-wiki users.
- Spanish participants needed to translate Commons metadata to themselves in order to write good captions in Spanish.
- The current task requires several different skills, such as image evaluation, caption writing, and translation (for reading Commons metadata from a non-English Wikipedia). There may be benefits and opportunities for separating out this task into multiple tasks in future so that users don't have to have all the skills in order to complete the task.
- Concept B clearly performed better for participants in both English and Spanish tests, particularly:
- Changes
- Do not show a preview of the suggested image on the card in the suggested edits feed.
- The onboarding tooltips worked well to help users understand the task. But they could be overwhelming or cluttering for smaller screens. Though we prefer to implement tooltips, we have decided to implement fullscreen overlays for onboarding in Iteration 1, because tooltips will take a substantially longer time to engineer well. We may implement tooltips in a future iteration.
- Image and image metadata need to be next to each other -- when they are in separate parts of the screen, users become confused.
- Because it is very important that users consider image metadata when making their decision and writing the caption, we need to increase the visibility of the metadata with clearer calls to read it.
- Include simple validation on the free-text caption, such as enforcing a minimum length for captions, or not allowing the filename to be part of the caption.
- Provide samples of good and bad captions in the explanation for the caption step.
- When users reject a suggestion and give the reason for the rejection, some of the reasons should not remove the suggestion from the queue, e.g. "I do not know this topic". Perhaps another user will be able to confidently make the match.
- Example captions: below are three image/article pairings used in the test and the actual captions written by user testers. This gives us a sense of the sorts of captions we can expect from newcomers. They all seem to be generally on the right track, though they range from more like "alt text" to more like captions. There are also a couple that miss the mark.
-
 Article: Edward Edwards (Royal navy officer)
Article: Edward Edwards (Royal navy officer)
"Drawing of the HMS Pandora by Robert Batty"
"The HMS Pandora, of which Admiral Edward Edwards captained in order to catch mutineers."
"An 1831 depiction of the HMS Pandora sinking"
"Royal Navy"
"Illustration of HMS Pandora sinking" -
 Article: Fiesque
Article: Fiesque
"Edouard Lalo, composer of the music of the Fiesque opera"
"Photo of Edouard Lalo, composer of Fiesque"
"Edouard Lalo - 1865"
"Eduard Lalo, around 1865"
These captions were translated from Spanish. -
 Article: Bahaettin Rahmi Bediz
Article: Bahaettin Rahmi Bediz
"A photo of Bahaettin Rahmi Bediz taken on 1st January 1924, pictured with his bicycle"
"Bahaettin Radmi Bediz on 1 January 1924"
"Rahmizadephoto1869"
"Rahnizade Bahaeddin Bediz. in uniform, standing next to a bicycle"



Final designs for Iteration 1
Based on the user test findings above, we created the set of designs that we are implementing for Iteration 1. The best way to explore those designs is here in the Figma file, which always contains the latest version.
Measurement
Leading indicators
Whenever we deploy new features, we define a set of "leading indicators" that we will keep track of during the early stages of the experiment. These help us quickly identify if the feature is generally behaving as expected and allow us to notice if it is causing any damage to the wikis. Each leading indicator comes with a plan of action in case the defined threshold is reached, so that the team knows what to do.
| Indicator | Plan of Action |
|---|---|
| Revert rate | This suggests that the community finds the "add an image" edits to be unconstructive. If the revert rate for "add an image" is substantially higher than that of unstructured tasks, we will analyze the reverts in order to understand what causes this increase, then adjust the task in order to reduce the likelihood of edits being reverted. |
| User rejection rate | This can indicate that we are suggesting a lot of images that are not good matches. If the rejection rate is above 40%, we will QA the image suggestion algorithm and adjust thresholds or make changes to improve the quality of the recommendations. |
| Over-acceptance rate | This might indicate that some users aren't actually applying judgment to their tasks, meaning we might want to implement different quality gates. (What percentage of users who have a complete session have never rejected or skipped an image? What percentage of users who have five or more complete sessions have never rejected or skipped an image? How many sessions across all users contained only acceptances?) |
| Task completion rate | This might indicate that there’s an issue with the editing workflow. If the proportion of users who start the "add an image" task and complete it is lower than 55% (completion rate for "add a link"), we investigate where in the workflow users leave and deploy design changes to enable them to continue. |
We collected data on usage of "add an image" from deployment on November 29, 2021 until December 14, 2021. "Add an image" has only been made available on the mobile website, and is given to a random 50% of registrations on that platform (excluding our 20% overall control group). We therefore focus on mobile users registered after deployment. This dataset excluded known test accounts, and does not contain data from users who block event logging (e.g. through their ad blocker).
Overall: The most notable thing about the leading indicator data is how few edits have been completed so far: only 89 edits over the first two weeks. Over the first two weeks of "add a link", almost 300 edits were made. That feature was deployed to both desktop and mobile users, but that alone is not enough to make up the difference. The leading indicators below give some clues. For instance, task completion rate is notably low. We also notice that people do not do many of these tasks in a row, whereas with "add a link", users do dozens in a row. This is a prime area for future investigation.
Revert rate: We use edit tags to identify edits and reverts, and reverts have to be done within 48 hours of the edit. The latter is in line with common practices for reverts.
| Task type | N edits | N reverts | Revert rate |
|---|---|---|---|
| Add an image | ٦٩ | ١٣ | ١٨٫٨% |
| Add a link | ٢٠٩ | ٤ | ١٫٩% |
| Copyedit | ٩٣ | ١٩ | ٢٠٫٤% |
The "add an image" revert rate is comparable to the copyedit revert rate, and it’s significantly higher than "add a link" (using a test of proportions). Because "add an image" has a comparable revert rate to unstructured tasks, the threshold described in the leading indicator table is not met, and we do not have cause for alarm. That said, we are still looking into why reverts are occurring in order to make improvements. One issue we've noticed so far is a large number of users saving edits from outside the "add an image" workflow. They can do this by toggling to the visual editor, but it is happening so much more often than for "add a link" that we think there is something confusing about the "caption" step that is causing users to wander outside of it.
Rejection rate: We define an edit “session” as reaching the edit summary dialogue or the skip dialogue, at which point we count whether the recommended image was accepted, rejected, or skipped. Users can reach this dialogue multiple times, because we think that choosing to go back and review an image or edit the caption is a reasonable choice.
| N accepted | % | N rejected | % | N skipped | % | N total |
|---|---|---|---|---|---|---|
| ٥٣ | ٤١٫٧ | ٣٨ | ٢٩٫٩ | ٣٦ | ٢٨٫٣ | ١٢٧ |
The threshold in the leading indicator table was a rejection rate of 40%, and this threshold has not been met. This means that users are rejecting suggestions at about the same rate as we expected, and we don't have reason to believe the algorithm is underperforming.
Over-acceptance rate: We reuse the concept of an "edit session" from the rejection rate analysis, and count the number of users who only have sessions where they accepted the image. In order to understand whether these users make many edits, we measure this for all users as well as for those with multiple edit sessions and five or more edit sessions. In the table below, the "N total" column shows the total number of users with that number of edit sessions, and "N accepted all" the number of users who only have edit sessions where they accepted all suggested images.
| Edits | N total | N accepted all | % |
|---|---|---|---|
| ≥1 edit | ٩٧ | ٣٤ | ٣٥٫١ |
| ≥2 edits | ٢١ | ٨ | ٣٨٫١ |
| ≥5 edits | ٠ | ٠ | ٠٫٠ |
It is clear that over-acceptance is not an issue in this dataset, because there are no users who have 5 or more completed image edits, and for those who have more than one, 38% of the users accepted all their suggestions. This is in the expected range, given that the algorithm is expected usually to make good suggestions.
Task completion rate: We define "starting a task" as having an impression of "machine suggestions mode". In other words, the user is loading the editor with an "add an image" task. Completing a task is defined as clicking to save the edit, or confirming that you skipped the suggested image.
| N Started a Task | N Completed 1+ Tasks | % |
|---|---|---|
| ٣١٣ | ٩٦ | ٣٠٫٧ |
The threshold defined in the leading indicator table is "lower than 55%", and this threshold has been met. This means we are concerned about why users do not make their way through the whole workflow, and we want to understand where they get stuck or drop out.
Add an Image Experiment Analysis
Review the full report: "Add an Image" Experiment Analysis, March 2024.
"Add an image" to a Section

On wikis where it is deployed, newcomers have access to the “add an image” structured task from their Newcomer homepage. The existing "add an image" task suggests article-level image suggestions for entirely unillustrated articles. The image is then added to the article's lead section to help illustrate the article's concept as a whole.

There will be onboarding for the task, followed by a specific suggestion (that includes the reason why the image is suggested). If the newcomer decides the image is a good fit for the article's section, then they receive guidance on caption writing. The structured task provides image details, further caption writing help if needed, and then prompts the newcomer to review and publish the edit.
A partnership with the Structured Data team
This is one aspect of the Structured Data Across Wikipedia project. This new task will provide image suggestions that are relevant to a particular section within an article. This section-level image suggestion task will be considered a more difficult task that will only be suggested to newcomers who are successful at the current article-level “add an image” task.
Read more about the Structured Data Across Wikimedia team’s work here: Section-level image suggestions.Hypotheses
- Structured editing experience will lower the barrier to entry and thereby engage more newcomers, and more kinds of newcomers than an unstructured experience.
- Newcomers with the workflow will complete more edits in their first session, and be more likely to return to complete more.
- Adding a new type of “add an image” task will increase the number of image suggestions available for each language.
Scope
Key deliverable: completion of the Section-Level Images (newcomer structured task) Epic (T321754).
Design
Screenshots from two mobile designs can be seen on the right. Section-level "add an image" designs are visible in this Figma file.
User testing
Initial user testing of designs was completed in April 2023 in English. Six testers were given instructions, asked to experiment with this section-level design prototype, and evaluate the easiness and enjoyableness of the task. Testers ranged in age from 18 to 55, were from 5 different countries, and most had not previously edited Wikipedia. Three of the testers were male, and three were female. They were asked to review two image suggestions, one was a "good" image suggestion and one was a "bad" image suggestion.
Some key take-aways from the user testing:
- The onboarding was understood by all participants: “Clear, easy to understand, straightforward.”
- Participants seemed to understand the task and that they needed to focus on the section when making their decision. One participant accepted a "bad" image suggestion:
- 2/6 participants accepted the "good" image suggestion (3 rejected the image, 1 participant skipped it).
- 5/6 participants rejected the "bad" image suggestion.
- Note: the algorithm that powers image suggestions should provide more "good" suggestions than "bad" suggestions, but the algorithm isn't perfect, which is why this task needs human review and is suitable for new editors.
- Some participants mentioned wanting more than one image to review per section: “One suggestion is not enough, maybe you can present more images to choose from so I can select the most appropriate image.”
Algorithm evaluation
The Growth team aims to ensure structured tasks for newcomers provide suggestions to newcomers that are accurate at least 70% of the time. We have conducted several rounds of evaluation to review the accuracy of the image suggestion algorithm.
In the initial evaluation, suggestions were still fairly inaccurate (T316151). Many images were suggested in sections that shouldn't have images, or the image related to one topic in the section but didn't represent the section as a whole. Based on feedback from this evaluation, the Structured Data team continued to work on logic and filtering improvements to ensure suggestions were more accurate (T311814).
In the second evaluation, on average, suggestions were much better (T330784). Of course results varied widely by language, but the average accuracy was fairly high for many wikis. However, there are some wikis in which the suggestions are still not good enough to present to newcomers, unless we only utilized the "good intersection" suggestions. That would severely limit the number of image suggestions available, so we are looking instead at increasing the confidence score of the suggestions we provide.
| wiki | % good alignment | % good intersection | % good p18/p373/lead image | total rated suggestions |
|---|---|---|---|---|
| arwiki | 71 | 91 | 54 | 511 |
| bnwiki | 28 | 86 | 26 | 204 |
| cswiki | 41 | 77 | 23 | 128 |
| enwiki | 76 | 96 | 75 | 75 |
| eswiki | 60 | 67 | 48 | 549 |
| frwiki | N.A. | N.A. | 100 | 3 |
| idwiki | 66 | 81 | 37 | 315 |
| ptwiki | 92 | 100 | 84 | 85 |
| ruwiki | 73 | 89 | 69 | 250 |
| overall | 64 | 86 | 57 | 2,120 |
It's good to note that this task will be Community configurable via Special:EditGrowthConfig. We hope to improve the task to the point that it can work well on all wikis, but communities will ultimately decide if this task is a good fit and should remain enabled.
Community consultation
A discussion with Growth pilot wikis is planned for May 2023 (T332530). We will post designs, plans, and questions at Arabic Wikipedia, Bengali Wikipedia, Czech Wikipedia, Spanish Wikipedia, as well as share further details here on MediaWiki.
Measurement
We decided to not deploy this feature in an A/B test and instead allow users to opt in to using it through the task selection dialogue on the Newcomer Homepage, or through the "Try a new task" post-edit dialogue that's part of the Levelling Up features. This meant that we focused on measuring a set of leading indicators to understand if the task was performing well. More details about this can be found in T332344.
We pulled data from Growth's KPI Grafana board from 2023-07-31 to 2023-08-28 (available here) for Section-Level and Article-Level suggestions. This timeframe was chosen because it should not be as much affected by the June/July slump in activity that we often see on the wikis. The end date is limited by the team shutting off image suggestions in late August (see T345188 for more information). This data range covers four whole weeks of data. While this dataset does not allow us to separate it by platform (desktop and mobile web), nor does it allow us more fine-grained user filtering, it was easily available and provides us with a reasonably good picture that's sufficient for this kind of analysis at this time. Using this dataset we get the overview of task activity shown in Table 1.
| Task type | Task clicks | Saved edits | Reverts | Task completion rate | Revert rate |
|---|---|---|---|---|---|
| Section-level | ١٬١٤٩ | ٦٨٨ | ٦٠ | ٥٨٫١% | ٩٫٠% |
| Article-level | ٦٬٨٠٠ | ٢٬٤١٤ | ١٠٥ | ٣٥٫٥% | ٤٫٣% |
We see from the table that the task completion rate for section-level image suggestions is high, on par with Add a Link (ref) when that was released. This is likely because the section-level task is something users either choose themselves in the task selection dialogue, or choose to try out after being asked through the "Try a new task" dialogue that's part of Levelling Up. Those users are therefore likely already experienced editors and don't have too many issues with completing this task.
The revert rate for the section-level task is higher than the article-level task. We don't think this difference is cause for concern for two reasons. First, it might be harder to agree that an article is clearly improved by adding a section-level image compared to adding an article-level image. Secondly, articles suggested for section-level images already have a lead image, which might mean that they're also longer and have more contributors scrutinizing the edit.