Wikimedia Apps/Team/Android/Machine Assisted Article Descriptions/Updates/it
Updates
Further changes
- We've used the same underlying machine-learning model for all of these experiments (so no re-training etc. of the actual model). What we've been adjusting throughout is how the user interacts with it.
- Our initial offline evaluation was of this model (Jan-April '23) lead us to put in place a few modifications to how users interacted with the model for the May-June 2023 piloting -- notably which outputs they could see (only higher confidence ones) and adjusting who could see the recommendations based on whether the article was a biography of a living person or not.
- The feedback from that pilot lead to us putting in place one final adjustment having to do with when a recommended article description included a year in it (only show it if there's support for that year in the article text because this was one source of hallucinations by the model). That's now part of the officially deployed model on LiftWing (the link I shared above) that Android users would see.
- At this point we aren't planning on any model updates beyond trying to reduce the latency of the model so Android users can see the recommendations more quickly. If we got feedback about errors that we thought we could address though, we'd try to make those fixes
August 2024
- We are beginning to reach out to some Wikis to implement the feature, based on the results from the experiment that was updated and published last January.
July 2024: API available through LiftWing
We appreciate everyone's patience as we've worked with the Machine Learning team to migrate the model to LiftWing. In August we will clean up the client side code to remove test conditions and add in improvements mentioned in the January 2024 update. In the following months we will reach out to different language communities to make the feature available to them in the app.
If you are a developer and would like to build a gadget using the API, you can read the documentation here.
Gennaio 2024: Risultati dell'esperimento
Lingue incluse nella valutazione:
- Arabo
- Ceco
- Tedesco
- Inglese
- Spagnolo
- Francese
- Gujarati
- Hindi
- Italiano
- Giapponese
- Russo
- Turco
Altre lingue monitorate dallo staff che non hanno avuto valutatori comunitari:
- Finlandese
- Kazako
- Coreano
- Birmano
- Olandese
- Rumeno
- Vietnamita
C'è una differenza tra media e mediana della valutazione degli edit Machine Accepted e quelli generati da umani (Human Generated)?:
| Edit valutati | Valutazione media | Mediana |
| Machine Accepted Edits | 4.1 | 5 |
| Human Generated Edits | 4.2 | 5 |
- Nota: 5 è stato il punteggio più alto possibile
Come ha funzionato il modello nelle diverse lingue?
| Lingua | Machine Accepted
Valutazione media degli edit |
Human Generated
Valutazione media degli edit |
Machine Avg.
più elevata? |
Raccomandare l'abilitazione della feature |
| ar* | 2.8 | 2.1 | VERO | No |
| cs | 4.5 | Not Applicable | Sì | |
| de | 3.9 | 4.1 | FALSO | Richiesti più di 50 edit |
| en | 4.0 | 4.5 | FALSO | Richiesti più di 50 edit |
| es | 4.5 | 4.1 | VERO | Sì |
| fr | 4.0 | 4.1 | FALSO | Richiesti più di 50 edit |
| gu* | 1.0 | Not Applicable | No | |
| hi | 3.8 | Not Applicable | Richiesti più di 50 edit | |
| it | 4.2 | 4.4 | FALSO | Richiesti più di 50 edit |
| ja | 4.0 | 4.5 | FALSO | Richiesti più di 50 edit |
| ru | 4.7 | 4.3 | VERO | Sì |
| tr | 3.8 | 3.4 | VERO | Sì |
| Altre lingue | Not Applicable | Not Applicable | Not Applicable | Possono abilitare su richiesta |
- Nota: la funzione non verrà abilitata senza preventivo coinvolgimento delle comunità.
* Indica le comunità linguistiche in cui non ci sono stati molti suggerimenti da valutare che riteniamo abbiano avuto un impatto sul punteggio
Quante volte sono stati accettati, modificati o rifiutati i testi generati dal sistema ?
| Tipo di modifica | % del totale dei Machine Edits |
| Accettati | 23.49% |
| Modificati | 14.49% |
| Rifiutati | 62.02% |
- Nota: rifiuto significa che la proposta della macchina non è stata selezionata anche se era disponibile. I suggerimenti delle macchine erano dietro un commento che diceva "Suggerimenti della macchina". Gli utenti che non hanno visto affatto le proposte della macchina entrano nel conteggio dei "rifiutati". Il rifiuto comunica quindi che l'utente ha preferito digitare la propria descrizione breve della voce.
Qual è stata la distribuzione delle descrizioni brevi Machine Accepted con una valutazione di 3 o più?
| Valutazione | Percentuale |
| < 3 | 10.0% |
| >= 3 | 90.0% |
Come cambia il punteggio delle descrizioni brevi Machine Accepted quando si considera anche l'esperienza degli utenti?
| Esperienza dell'utente | Valutazione media | Mediana della valutazione |
| Sotto le 50 modifiche | 3.6 | 4 |
| Sopra le 50 modifiche | 4.4 | 5 |
Il nostro esperimento ha testato due modalità per vedere quale fosse più precisa e performante. Per evitare distorsioni, il posizionamento del suggerimento all'utente cambiava di volta in volta posizione. I risultati sono:
| Modalità selezionata | Valutazione media | % Distribuzione |
| 1 | 4.2 | 64.7% |
| 2 | 4.0 | 35.3% |
- Nota: Quando la funzione verrà attivata mostrerà solo la modalità 1.
Con quale frequenza le persone apportano modifiche al suggerimento della macchina prima di pubblicarlo?
| Tipo di modifica | Distribuzione |
| Machine Accepted non viene modificata | 61.85% |
| Machine Accepted viene modificata | 38.15% |
In che modo gli utenti che modificano il suggerimento della macchina influiscono sull'accuratezza?
| Valutazione delle modifiche | Valutazione media |
| Non modificata | 4.2 |
| Modificata | 4.1 |
Nota: poiché non c'è un impatto sull'accuratezza se un utente modifica o meno il suggerimento, non vediamo la necessità di richiedere agli utenti di apportare una modifica alla raccomandazione, ma dovremmo comunque mantenere un'interfaccia utente che incoraggi le modifiche al suggerimento della macchina.
Quante volte un valutatore ha detto che avrebbe cambiato o riscritto una modifica in base al fatto che fosse suggerita dalla macchina o generata dall'uomo?
| Graded Edits: | % edits che annullerebbe | % edits che riscriverebbe |
| Suggerimenti accettati | 2.3% | 25.0% |
| Suggerimento visto ma descrizione scritta dall'utente | 5.7% | 38.4% |
| Modifica generata da umano e nessun suggerimento | 15.0% | 25.8% |
Nota: abbiamo definito "annulla" quando la modifica è così imprecisa che non vale la pena di provare a fare una piccola modifica per migliorarla come patroller. Il termine modifica è stato definito quando un patroller si limita a modificare ciò che è stato pubblicato dall'utente per migliorarlo. Nel corso dell'esperimento sono state annullate solo 20 modifiche automatiche in tutti i progetti, un dato non statisticamente significativo, quindi non abbiamo potuto confrontare gli annullamenti effettivi, ma ci siamo basati sulle raccomandazioni dei valutatori. Solo due comunità linguistiche hanno le loro descrizioni brevi degli articoli su Wikipedia, il che significa che il patrolling è meno frequente per la maggior parte delle comunità linguistiche, dato che le descrizioni sono ospitate su Wikidata.
Quali informazioni abbiamo ottenuto grazie alla funzione di reportistica della funzione?
Lo 0,5% degli utenti ha segnalato la funzione. Di seguito è riportata una distribuzione del tipo di feedback ricevuto:
| Feedback/Reazione | % Distribuzione del feedback |
| Informazioni insufficienti | 43% |
| Suggerimento inadeguato | 21% |
| Date errate | 14% |
| Non vedo la descrizione | 7% |
| "Superfluo" | 7% |
| Sintassi errata | 7% |
La funzione ha un impatto sulla retention?
| Periodo di retention | Guppo 0
(No treatment) |
Gruppo 1 e 2 |
| 1-giorno di tasso medio di ritorno: | 35.4% | 34.9% |
| 3-giorni di tasso medio di ritorno: | 29.5% | 30.3% |
| 7-giorni di tasso medio di ritorno: | 22.6% | 24.1% |
| 14-giorni di tasso medio di ritorno: | 14.7% | 15.8% |
- Nota: gli utenti esposti alle descrizioni brevi Machine Assisted hanno avuto un tasso di ritorno leggermente più alto rispetto agli utenti non esposti alla funzione
Prossimi passi:
L'esperimento è stato condotto su servizi cloud, che non sono una soluzione sostenibile. Ci sono abbastanza indicatori positivi per rendere la funzione disponibile alle comunità che la desiderano. Il team delle applicazioni lavorerà in collaborazione con il nostro Machine Learning per migrare il modello su Liftwing; una volta migrato e testato a sufficienza per le prestazioni, ci rivolgeremo nuovamente alle nostre comunità linguistiche per determinare dove abilitare la funzione e quali ulteriori miglioramenti possono essere apportati al modello. Le modifiche che attualmente prioritarie includono:
- Escludere le biografie di persone viventi (BLP): Durante l'esperimento abbiamo permesso agli utenti con più di 50 modifiche di aggiungere descrizioni alle biografie di persone viventi con l'aiuto dell'assistenza automatica. Riconosciamo che ci sono preoccupazioni riguardo al suggerimento di descrizioni brevi su questi articoli. Sebbene non abbiamo riscontrato problemi relativi alle biografie di persone viventi, siamo lieti di non mostrare suggerimenti sulle BLP.
- Usare solo la modalità 1: la modalità 1 ha costantemente superato la 2 per quanto riguarda i suggerimenti. Di conseguenza, mostreremo solo una raccomandazione, e sarà quella della modalità 1.
Modificare l'onboarding e la guida: Durante l'esperimento è stata inserita una schermata di onboarding sui suggerimenti delle macchine. Quando rilasceremo la funzione, aggiungeremo una guida sui suggerimenti automatici. Sarebbe utile ricevere un feedback dalla comunità su quali indicazioni vorrebbero che fornissimo agli utenti per scrivere descrizioni brevi efficaci degli articoli, in modo da migliorare l'onboarding.
Se ci sono altri errori evidenti, si prega di lasciare un messaggio sulla pagina di discussione del progetto, in modo da poterli risolvere. Un esempio di errore evidente è la visualizzazione di date errate. Abbiamo notato questo errore durante i test sull'applicazione e abbiamo aggiunto un filtro che impedisce alle descrizioni delle raccomandazioni di includere date che non sono menzionate nel testo dell'articolo. Abbiamo anche notato che le pagine di disambiguazione venivano raccomandate dal modello originale e abbiamo filtrato le pagine di disambiguazione dal lato client, una modifica che intendiamo mantenere. Anche altre cose, come la maiuscola della prima lettera, sarebbero una correzione generale che potremmo fare, perché esiste un'euristica chiara che potremmo usare per implementarla.
Per le lingue in cui il modello non funziona abbastanza bene da essere distribuito, la cosa più utile è aggiungere più descrizioni brevi di voci in quella lingua, in modo che la riqualificazione del modello abbia più dati su cui basarsi. A questo punto, però, non c'è una data o una frequenza prestabilita per la riqualificazione del modello, ma possiamo collaborare con il team Research and Machine Learning per dare priorità a questa operazione quando le comunità la richiedono.
July 2023: Early Insights from 32 Days of Data Analysis: Grading Scores and Editing Patterns
We can not complete our data analysis until all entries have been graded so that we have an accurate grading score. However we do have early insights we can share. These insights are based on 32 days of data:
- 3968 Articles with Machine Edits were exposed to 375 editors.
- Note: Exposed does not mean selected.
- 2125 Machine edits were published by 256 editors
- Editors with 50+ edits completed three times the amount of edits per unique compared to editors with less than 50 edits
May 2023: Experiment Deactivated & Volunteers Evaluate Article Short Descriptions
The experiment has officially been deactivated and we are now in a period of edits being graded.
Volunteers across several language Wikis have begun to evaluate both human generated and machine assisted article short descriptions.
We express our sincere gratitude and appreciation to all the volunteers, and have added a dedicated section to honor their efforts on the project page. Thank you for your support!
We are still welcoming support from the following language Wikipedias for grading: Arabic, English, French, German, Italian, Japanese, Russian, Spanish, and Turkish languages.
If you are interested in joining us for this incredible project, please reach out to Amal Ramadan. We look forward to collaborating with passionate individuals like you!
April 2023: FAQ Page and Model Card
We released our experiment in the 25 mBART languages this month and it will run until mid-May. Prior to release we added a model card to our FAQ page to provide transparency into how the model works.
-
 Suggested edits home
Suggested edits home -
 Suggested edits feed
Suggested edits feed -
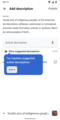 Suggested edits onboarding
Suggested edits onboarding -
 Active text field
Active text field -
 Dialog Box
Dialog Box -
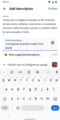 What happens after tapping suggestions
What happens after tapping suggestions -
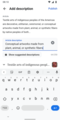 Manual text addition
Manual text addition -
 The preview
The preview -
 Tapping the report flag
Tapping the report flag -
 Confirmation
Confirmation -
 Gender bias support text
Gender bias support text











This is the onboarding process:
-
 Article Descriptions Onboarding
Article Descriptions Onboarding -
 Keep it short
Keep it short -
 Machine Suggestions
Machine Suggestions -
 Tooltip
Tooltip




January 2023: Updated Designs
After determining that the suggestions could be embedded in the existing article short descriptions task the Android team made updates to our design.
-
 Tooltip to as onboarding of feature
Tooltip to as onboarding of feature -
 Once the tooltip is dismissed the keyboard becomes active
Once the tooltip is dismissed the keyboard becomes active -
 Dialog appears with suggestions when users tap "show suggested descriptions"
Dialog appears with suggestions when users tap "show suggested descriptions" -
 Tapping a suggestion populates text field and publish button becomes active
Tapping a suggestion populates text field and publish button becomes active




If a user reports a suggestion, they will see the same dialog as we proposed in our August 2022 update as the what will be seen if someone clicks Not Sure.
This new design does mean we will allow users to publish their edits, as they would be able to without the machine generated suggestions. However, our team will patrol the edits that are made through this experiment to ensure we do not overwhelm volunteer patrollers. Additionally, new users will not receive suggestions for Biographies of Living Persons.
November 2022: API Development
The Research team put the model on toolforge and tested the performance of the API. Initial insights found that it took 5-10 seconds to generate suggestions, which also varied depending on how many suggestions were being shown. Performance improved as the number of suggestions generated decreased. Ways of addressing this problem was by preloading some suggestions, restricting the number of suggestions shown when integrated into article short descriptions, and altering user flows to ensure suggestions can be generated in the background.
August 2022: Initial Design Concepts and Guardrails for Bias
User story for Discovery
When I am using the Wikipedia Android app, am logged in, and discover a tooltip about a new edit feature, I want to be educated about the task, so I can consider trying it out. Open Question: When should this tooltip be seen in relation to other tooltips?
User story for education
When I want to try out the article short descriptions feature, I want to be educated about the task, so my expectations are set correctly.


User story for adding descriptions
When I use the article short descriptions feature, I want to see articles without a description, I want to be presented with two suitable descriptions and an option to add a description of my own, so I can select or add a description for multiple articles in a row.
-
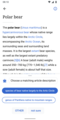 Concept for selecting a suggested article description
Concept for selecting a suggested article description -
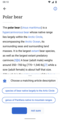 Design concept for a user deciding the description should be an alternative to what is listed
Design concept for a user deciding the description should be an alternative to what is listed -
 Design concept for a user editing a suggestion before hitting publish
Design concept for a user editing a suggestion before hitting publish -
 Design concept for what users see when pressing other
Design concept for what users see when pressing other -
 Screen displaying options for if a user says they are not sure what the correct article description should be
Screen displaying options for if a user says they are not sure what the correct article description should be





Guardrails for bias and harm
The team generated possible guardrails for bias and harm:
- Harm: problematic text recommendations
- Guardrail: blocklist of words never to use
- Guardrail: check for stereotypes – e.g., gendered language + occupations
- Harm: poor quality of recommendations
- Guardrail: minimum amount of information in article
- Guardrail: verify performance by knowledge gap
- Harm: recommendations only for some types of articles
- Guardrail: monitor edit distribution by topic