CAPTCHA
CAPCHAs (abreviação de "Teste de Turing Público Completamente Automatizado para diferenciar computadores e humanos") são utilizados nos wikis da Wikimedia, por meio da extensão ConfirmEdit ConfirmEdit, como um meio de prevenir ostensivamente spam e dissuadir spammers. Na maioria dos wikis, um usuário pode clicar em um CAPTCHA ao tentar criar uma conta, criar uma nova página ou adicionar um link externo para a página.
No pt.wiki, no período de 2008–2013, o CAPTCHA também foi mostrado "temporariamente" em todas as edições de usuários não registrados e novos, supostamente para reduzir o vandalismo (ver discussão e bugzilla:41745).
Existe um número de problemas com a implementação atual do CAPTCHA.
- Estão disponíveis apenas em inglês (bugzilla:5309): as palavras utilizadas pelos nossos CAPTCHAs, independentemente da forma como são criados, devem estar no idioma do usuário. Um número desconhecido de novos usuários e editores são perdidos por pessoas que não falam inglês.
- Isso acaba violando o princípio da acessibilidade (bugzilla:4845).
- Eles não impedem efetivamente que os bots enviem spam.
Alternativas que podem ser implementadas no futuro
CAPTCHA
As imagens do Captcha não requerem entrada de texto, o que ajuda em problemas de mobilidade e internacionalização. Algumas ideias baseadas em imagens:
- Encontre a única diferença no grupo (view prototype). Várias imagens da mesma categoria (por exemplo, pessoas) são mostradas misturadas com uma imagem de uma categoria diferente (por exemplo, gato). Humanos deveriam ser capazes de reconhecer qual é a diferença entre elas. Observe que neste caso a pergunta é sempre a mesma (encontre a diferente) e as categorias utilizadas não são expostas ao usuário.
- Encontre todas as imagens de um grupo (view prototype). Imagens de duas ou mais categorias são apresentadas juntas. O usuário é explicitamente solicitado a encontrar todas as imagens de um determinado tipo ou grupo (por exemplo, todas as imagens de pessoas usando óculos)
- Encontre imagens em comum com o pedido (view prototype). São apresentadas ao usuário imagens que contêm alguns elementos marcados e opções para escolher a legenda correta (por exemplo, é um pássaro? é um avião?).
A parte difícil aqui é como criar imagens e verificar dados de uma forma que não seja explorável por spambots. Você precisa de um conjunto muito grande de CAPTCHAs (centenas de milhares, de preferência), caso contrário, um invasor pode simplesmente mapear seu banco de dados CAPTCHA. Se você usar um repositório de imagens públicas (como o Commons) ou uma fonte de dados pública (como as categorias do Commons), é provável que um invasor consiga combinar o CAPTCHA com a fonte e descobrir a solução a partir disso.
-
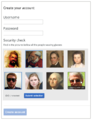 Encontre todos os captcha combinados.
Encontre todos os captcha combinados. -
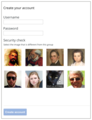 Encontre todo o captcha diferente.
Encontre todo o captcha diferente. -
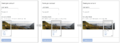 Associe os panoramas do captcha
Associe os panoramas do captcha


Substituindo CAPTCHA por um honeypot
Uma possibilidade de evitar problemas de localização com o CAPTCHA é simplesmente removê-lo e substituí-lo por um honeypot.
Um clone reCAPTCHA desenvolvido internamente
Escreva uma versão do reCAPTCHA que use imagens de documentos que foram processadas pela MediaWiki's Extensão ProofreadPage do Wikisource:WikiCAPTCHA. Em outras palavras, um CAPTCHA que alimenta o ProofreadPage com dados para aumentar seu processamento de OCR. Você pode construir em código existente. É importante notar que "o reCAPTCHA não detém patentes específicas para a tecnologia por trás de seus algoritmos CAPTCHA de texto (pelo menos nenhuma que eles discutam em seu site ou possam ser encontradas no site do US Patents & Trademark Office", de acordo com um blogueiro [1] ).
Também discutido na Wikimania 2012 com a apresentação Wikicaptcha: uma solução semelhante ao ReCAPTCHA para Wikisource
A vantagem desta abordagem é que podemos transformar a força de trabalho latente atualmente desperdiçada no CAPTCHA em lucro para um projeto da Wikimedia (Wikisource); e que podemos começar com um conjunto de dados limitado. Na verdade, trabalhando no modo reCaptcha, poderíamos criar algum tipo de conjunto bootstrap de dados, depois mostrar às pessoas uma mistura de captchas com soluções conhecidas e desconhecidas, assim usar as conhecidas para verificação e as desconhecidas para gerar mais dados. Mas isso não é fácil e deve receber um foco significativo no projeto se você quiser um sistema CAPTCHA que tenha alguma utilidade prática no final.
Acessibilidade
A acessibilidade do nosso CAPTCHA atual é extremamente ruim. Se o usuário tiver problemas de visão ou usar um leitor de tela, o CAPTCHA baseado em texto será quase totalmente inacessível para ele. Alguns de nossos maiores wikis resolvem isso por meio de um sistema de solicitação de conta administrado por voluntários. Alternativas como imagens de CAPTCHAs ainda violam os princípios de acessibilidade (bugzilla:4845), uma alternativa como um CAPTCHA de áudio poderia ser considerada, mas ainda assim não conseguiria fornecer acessibilidade para pessoas surdo cegas.
Veja também
- Admin tools development, a área de Engenharia da Wikimedia responsável por esta e outras ferramentas
- Bug 38640
- Research:Account creation UX/CAPTCHA
- You (probably) don't need ReCAPTCHA (2019)
- TEDxCMU -- Luis von Ahn -- Duolingo: The Next Chapter in Human Computation
- Discussões abertas recentemente
- Captchas e pessoas que não falam inglês parte I and parte II
- Wikipedia CAPTCHA repair (2011-11-03): «Agora que o CAPTCHA da Wikipedia foi totalmente quebrado por Burzstein et. al."Pontos fortes e fracos do CAPTCHA baseado em texto" [...] Reformulei o script Python de geração de imagens CAPTCHA da era 2005 no mecanismo CAPTCHA» – Código ainda aguarda por mais revisores.
- Suggestion: Substitua CAPTCHA por abordagens melhores (Julho de 2012)
- Sites proeminentes que não usam CAPTCHA
- Outros recursos
- Bots Are Better than Humans at Solving CAPTCHAs (on An Empirical Study & Evaluation of Modern CAPTCHAs, 2023)
- Asirra: A CAPTCHA that Exploits Interest-Aligned Manual Image Categorization, CCS’07, Outubro 29–Novembro 2, 2007, Alexandria, Virginia, USA. (Contém referências a outros artigos úteis sobre CAPTCHA.)
- Philippe Golle. 2008. Machine learning attacks against the Asirra CAPTCHA. In Anais da 15ª Conferência ACM sobre Segurança de Computadores e Comunicações (CCS '08). ACM, New York, NY, USA, 535-542. DOI=10.1145/1455770.1455838